Chez Smartpoint, nous assistons à une nouvelle révolution industrielle axée sur la génération d’intelligence grâce à l’IA … et cette révolution nécessite des infrastructures adaptées aux nouvelles exigences des entreprises, notamment en matière de gestion de volumes massifs et diversifiés de données. Nous pensons que le prochain axe majeur d’investissement sera la couche d’infrastructure de données, indispensable pour donner vie à des applications d’IA personnalisées.
L’infrastructure de données : fondation de la révolution IA
Les infrastructures de données doivent évoluer pour gérer des données non structurées à grande échelle, telles que les vidéos, images, audios, et même les données spatiales ! Avec l’essor de l’IA générative (GenAI), la qualité des données devient primordiale, non seulement pour l’entraînement des modèles, mais aussi pour leur inférence. La capacité à acquérir, nettoyer, transformer et organiser ces données est désormais un facteur clé de réussite.
D’ailleurs, le marché mondial des infrastructures IA connaît une croissance fulgurante. Il est estimé à 68,46 milliards de dollars en 2024 et pourrait atteindre 171,21 milliards de dollars d’ici 2029, avec un taux de croissance annuel moyen (CAGR) de 20,12 %. Cette progression est alimentée par l’adoption rapide de l’IA dans des secteurs variés, allant des grandes entreprises aux startups.
Automatisation et pipelines de données optimisés par l’IA
L’une des principales avancées concerne l’automatisation des pipelines de données. Grâce à l’IA, des workflows end-to-end peuvent être mis en place pour gérer le traitement des données non structurées, de leur extraction à leur stockage en passant par leur transformation. Cela inclut des technologies comme le chunking (fractionnement des données en petites portions), l’indexation et la génération d’embeddings (représentations vectorielles) qui permettent une recherche plus rapide et pertinente. Cette approche devient indispensable dans des applications d’IA conversationnelle et d’agents autonomes.
Impact de l’inférence IA et essor de l’edge computing
L‘inférence IA, qui consiste à utiliser des modèles pour prendre des décisions en temps réel, est en pleine essor. Cet engouement est notamment soutenu par le edge computing, qui rapproche le traitement des données de leur source pour réduire les latences et optimiser les performances, tout en minimisant les coûts liés à la transmission des données vers le cloud. Cette technologie devient primordiale dans des secteurs tels que l’industrie manufacturière et évidemment la santé.
La récupération augmentée (RAG) : maximiser l’efficacité des applications IA
Une des innovations majeures observées dans les infrastructures de données est la génération augmentée par récupération (RAG). Cette méthode permet aux entreprises d’activer leurs données pour fournir des réponses plus précises et à jour via des modèles de langage (LLM). En combinant les données internes avec des requêtes, le RAG permet d’améliorer considérablement la fiabilité et la personnalisation des réponses générées par l’IA. Cela constitue un avantage concurrentiel pour les entreprises qui cherchent à fournir des expériences utilisateurs plus précises et crédibles.
Une gestion éthique et durable des données
Chez Smartpoint, nous croyons fermement à l’importance d’une gestion responsable et éthique des infrastructures de données. Nous nous engageons à éviter le Data Swamp, où des données non pertinentes s’accumulent, en nous concentrant sur la collecte et l’exploitation des données à forte valeur ajoutée. Cette approche permet non seulement d’améliorer la performance opérationnelle, mais aussi de respecter les régulations en matière de confidentialité, telles que le RGPD, tout en adoptant une démarche durable pour un usage plus responsable des ressources informatiques.
… Une infrastructure résiliente pour un avenir axé sur l’IA
Les infrastructures de données sont en pleine transformation sous l’impulsion de l’IA. Chez Smartpoint, pure player data depuis 2006, nous aidons nos clients à adapter leur architecture aux besoins croissants de l’IA, tout en assurant une gestion responsable et éthique des données. Ces évolutions permettront non seulement d’améliorer les performances des modèles IA, mais aussi d’offrir aux entreprises les moyens de se démarquer dans un marché toujours plus compétitif.
LAISSEZ-NOUS UN MESSAGE
Les champs obligatoires sont indiqués avec *.
Architecture
IA et Data Architecture : Révolutionnez la gestion et l’analyse de vos données.
Exploitez la puissance de l’IA pour automatiser, optimiser et analyser vos données avec des architectures data modernes. Découvrez les avantages, les cas d’utilisation et les étapes clés pour adopter ce changement porteur d’une transformation profonde.
L’intelligence artificielle (IA) transforme en profondeur le monde de la gestion et de l’analyse des données. En intégrant des technologies d’IA dans l’architecture des données, les entreprises peuvent automatiser des processus complexes, améliorer la précision des analyses et prendre des décisions basées sur des insights profonds et continuellement mis à jour.
Dans cet article d’expert, nous explorons les avantages de l’adoption d’une architecture data moderne avec l’IA. Nous couvrons les points suivants :
Automatisation des processus de données : L’IA peut automatiser la collecte, le nettoyage, la transformation et l’analyse des données, réduisant ainsi le temps et les ressources nécessaires à la gestion des données.
Intelligence et insights : L’IA peut générer des insights précieux à partir des données, permettant aux entreprises de prendre des décisions plus éclairées et d’optimiser leurs opérations.
Cas d’utilisation : Nous présentons des exemples concrets d’entreprises qui utilisent l’IA pour améliorer leur gestion et leur analyse des données.
Étapes clés pour adopter une architecture data moderne avec l’IA : Nous fournissons des conseils pratiques pour aider les entreprises à démarrer leur parcours vers une architecture data moderne avec l’IA.
En adoptant une architecture data moderne avec l’IA, les entreprises peuvent :
Réduire les coûts de gestion des données
Améliorer la qualité et la précision des données
Accélérer le processus de prise de décision
Développer de nouveaux produits et services
Gagner un avantage concurrentiel
1. L’IA pour l’automatisation des processus data
L’automatisation des processus est l’un des apports majeurs de l’IA dans l’architecture des données. Voici quelques domaines où l’IA joue un rôle crucial :
Collecte et Ingestion des données : Les systèmes d’IA peuvent automatiser la collecte de données à partir de sources diverses, y compris les données structurées et non structurées, les flux de données en temps réel et les bases de données traditionnelles. Des algorithmes de machine learning permettent de filtrer, nettoyer et normaliser ces données en temps réel, améliorant ainsi leur qualité dès le départ.
Nettoyage et préparation des Données : L’IA peut détecter et corriger automatiquement les anomalies, les doublons et les valeurs manquantes dans les jeux de données. Elle applique des règles de validation et de transformation des données, rendant ces dernières prêtes pour l’analyse sans intervention humaine.
Optimisation des requêtes et des analyses : Les moteurs de recommandation alimentés par l’IA peuvent suggérer des requêtes optimisées et des analyses prédictives en fonction des comportements passés des utilisateurs et des patterns détectés dans les données.
2. Intelligence et Insights : L’IA au service de l’analyse avancée
L’IA apporte une dimension d’intelligence et de prédiction dans l’architecture des données, permettant des analyses plus avancées et pertinentes :
Analyse prédictive : En exploitant des algorithmes de machine learning, les systèmes peuvent prévoir des tendances futures à partir des données historiques. Cela est particulièrement utile pour les prévisions de ventes, la gestion des stocks, la maintenance prédictive et la détection de fraudes.
Analyse prescriptive : L’IA ne se contente pas de prédire les tendances, elle peut également prescrire des actions à entreprendre pour atteindre des objectifs spécifiques. Par exemple, dans le domaine du marketing, l’IA peut recommander les meilleures actions à entreprendre pour optimiser les campagnes publicitaires en temps réel.
Traitement du Langage Naturel (NLP) : Les technologies de NLP permettent de comprendre et d’analyser les données textuelles non structurées comme les commentaires des clients, les avis sur les produits, et les rapports d’analyse. Cela ouvre de nouvelles perspectives pour l’analyse des sentiments, la surveillance de la réputation et la détection des tendances émergentes.
3. Cas d’usages de l’IA dans les architectures Data
Détection des fraudes : Les algorithmes de machine learning peuvent analyser des millions de transactions en temps réel pour détecter des patterns de fraude potentiels, offrant une protection accrue et une réactivité optimale.
Maintenance prédictive : En analysant les données issues des capteurs IoT installés sur les machines, l’IA peut prédire les pannes avant qu’elles ne surviennent, permettant ainsi de planifier les interventions de maintenance et d’optimiser les opérations.
Personnalisation des expériences clients : Les systèmes d’IA analysent les comportements des utilisateurs pour offrir des recommandations de produits personnalisées, améliorant ainsi l’engagement et la satisfaction des clients.
4. Défis et considérations éthiques
Biais algorithmiques : Il est crucial de s’assurer que les algorithmes d’IA ne reproduisent pas ou n’amplifient pas les biais présents dans les données d’entraînement. Une gouvernance stricte et une surveillance continue des modèles sont nécessaires pour garantir l’équité et la transparence.
Confidentialité des données : L’utilisation de l’IA nécessite souvent l’accès à des volumes importants de données, ce qui pose des défis en matière de confidentialité et de protection des données. Les entreprises doivent adopter des pratiques robustes de sécurité des données et se conformer aux réglementations en vigueur, telles que le RGPD.
Explicabilité et transparence : Les décisions prises par des algorithmes d’IA doivent être explicables et transparentes pour gagner la confiance des utilisateurs. Il est essentiel de développer des modèles d’IA interprétables et de documenter les processus décisionnels.
5. L’IA comme catalyseur d’innovation en architecture Data
L’intégration de l’IA dans l’architecture des données ne se limite pas à l’automatisation et à l’analyse avancée. Elle ouvre également la voie à l’innovation continue :
IA et Edge Computing : L’intégration de l’IA avec le edge computing permet de traiter les données au plus près de leur source, réduisant ainsi la latence et permettant des actions en temps réel, cruciales pour des secteurs comme la santé ou l’industrie 4.0.
Apprentissage Automatique en Continu : Les systèmes d’IA peuvent être conçus pour apprendre en continu à partir des nouvelles données, s’adaptant ainsi aux changements et améliorant leur précision et leur efficacité au fil du temps.
Plateformes d’IA en tant que Service (AIaaS) : Les solutions AIaaS offrent aux entreprises la possibilité de déployer rapidement des capacités d’IA sans avoir à investir massivement dans des infrastructures ou des compétences spécialisées, accélérant ainsi l’adoption de l’IA.
l’IA est un levier puissant pour transformer l’architecture des données, rendant les systèmes plus intelligents, plus automatisés et plus performants. Les entreprises qui intègrent l’IA dans leur architecture de données sont mieux équipées pour exploiter le plein potentiel de leurs données, innover en continu et maintenir un avantage concurrentiel durable.
Prêt à transformer votre gestion et votre analyse des données ? Contactez-nous dès aujourd’hui pour discuter de la façon dont l’IA peut vous aider à atteindre vos objectifs.
Quelles architectures de Real-time data processing pour avoir une vision immédiate ?
Dans un monde de plus en plus interconnecté où la rapidité et l’agilité sont facteurs de succès pour les organisations, le traitement des données en temps réel n’est plus un luxe mais une nécessité. Les entreprises ont besoin d’une vision immédiate de leur data pour prendre des décisions éclairées et réagir en temps réel aux événements marché. Le traitement des données en temps réel devient alors un enjeu crucial pour rester compétitif.
Chez Smartpoint, nous concevons des architectures permettant aux entreprises de réagir instantanément aux données entrantes, assurant ainsi un véritable avantage compétitif sur des marchés qui demandent de la réactivité.
1. Fondamentaux des architectures temps réel
Le traitement des données en temps réel se définit comme la capacité à ingérer, traiter et analyser des données au fur et à mesure qu’elles sont générées, sans délai significatif. Cela permet d’obtenir une vue actualisée en permanence de l’activité de l’entreprise et de réagir instantanément aux événements. C’est une réponse directe à l’éphémère « fenêtre d’opportunité » où les données sont les plus précieuses.
Définition et Composants Clés
Des collecteurs de données aux processeurs de streaming, en passant par les bases de données en mémoire, chaque composant est optimisé pour plus de vitesse et d’évolutivité. La réactivité, la résilience et l’élasticité sont les principes fondamentaux de conception de ce type d’architecture. Cela implique des choix technologiques robustes et une conception architecturale qui peut évoluer dynamiquement en fonction du volume des données. Une architecture de Reel-time data processing a une forte tolérance aux pannes, sans perte de données afin d’être en capacités de reprendre le traitement là où il s’était arrêté, garantissant ainsi l’intégrité et la continuité des opérations.
Plusieurs architectures de données peuvent être utilisées pour le traitement en temps réel, chacune avec ses avantages et ses inconvénients :
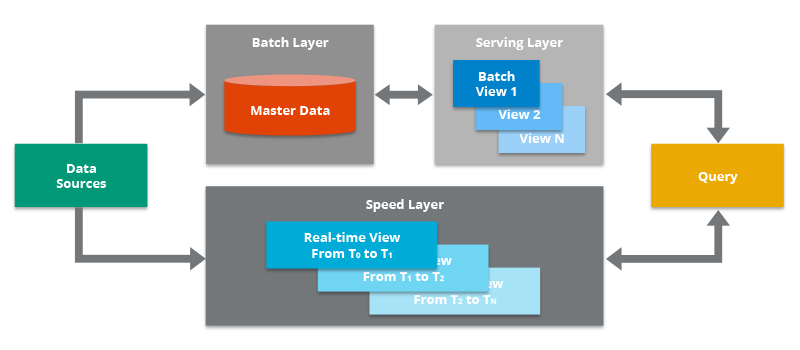
1.1 Lambda Architecture
Principe : Deux pipelines distinctes traitent les données en temps réel et en batch. La pipeline temps réel offre une faible latence pour les analyses critiques, tandis que le pipeline batch assure la cohérence et la complétude des données pour des analyses plus approfondies.
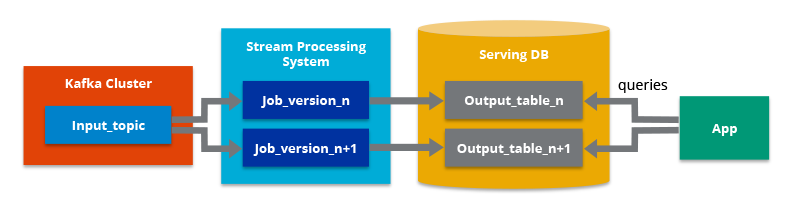
Principe : Unification du traitement des données en temps réel et en batch en un seul pipeline. Cette approche simplifie l’architecture et réduit les coûts de maintenance.
Principe : Se concentrent sur le traitement des données en temps réel en tant que flux continus. Cette approche offre une grande flexibilité et permet de réagir rapidement aux changements dans les données.
Technologies
: Apache Kafka, Apache Storm, Apache Flink
Outils : Apache Beam, Amazon Kinesis, Google Cloud Dataflow
Avantages : Flexibilité, scalabilité et adaptabilité aux nouveaux types de données.
Inconvénients : Complexité de la mise en œuvre et nécessité d’une expertise en streaming de données.
Cas d’utilisation : Surveillance des performances du réseau informatique en temps réel.
Technologie : Apache Kafka ingère les données des capteurs réseau, Apache Storm les traite pour détecter les anomalies et les visualiser en temps réel.
Exemple : Amazon utilise des architectures basées sur les flux de données pour surveiller ses infrastructures en temps réel.
Architecture Lambda++: Combine les avantages des architectures Lambda et Kappa pour une meilleure flexibilité et évolutivité.
Apache Beam : Plateforme unifiée pour le traitement des données en temps réel et en batch.
2. Comment choisir la bonne architecture ?
Le choix de l’architecture de données pour le traitement en temps réel dépend de plusieurs facteurs :
Nature des données: Volume, variété, vélocité et format des données à traiter.
Cas d’utilisation: Besoins spécifiques en termes de latence, de performance et de complexité des analyses.
Compétences et ressources disponibles : Expertises en interne ou recourt à une cabinet spécialisé comme Smartpoint et budget alloué à la mise en œuvre et à la maintenance de l’architecture.
Architecture
Latence
Performance
Scalabilité
Coût
Lambda
Haute
Bonne
Bonne
Élevé
Kappa
Faible
Bonne
Bonne
Moyen
Streaming data architecture
Faible
Excellente
Excellente
Variable
Cas d’usages
Amélioration de l’expérience client Par exemple, la capacité à réagir en temps réel aux comportements peut transformer l’expérience utilisateur, rendant les services plus réactifs et les offres plus personnalisées.
Optimisation opérationnelle La maintenance prédictive, la détection des fraudes, et l’ajustement des inventaires en temps réel sont d’autres exemples d’opérations améliorées par cette architecture.
3. Technologies et outils pour le traitement en temps réel
Kafka et Stream Processing Apache Kafka est une référence pour la gestion des flux de données en temps réel, souvent associé à des outils comme Apache Storm ou Apache Flink pour le traitement de ces flux.
Base de données en mémoire Des technologies comme Redis exploitent la mémoire vive pour le traitement et des accès ultra-rapides aux données.
Frameworks d’Intelligence Artificielle Des frameworks comme TensorFlow ou PyTorch sont employés pour inférer en temps réel des données en mouvement, pour des résultats immédiats.
4. Cas Pratiques par Secteur
Finance : Détection de fraude en millisecondes pour les transactions de marché.
E-commerce : Mise à jour en temps réel des stocks et recommandation de produits personnalisés.
Télécommunications : Surveillance de réseau et allocation dynamique des ressources pour optimiser la bande passante.
Santé : Surveillance en temps réel des signes vitaux pour une intervention rapide en cas d’urgence.
La complexité de l’ingénierie, la nécessité d’une gouvernance des données en temps réel, la gestion de la cohérence, la sécurité et les règlementations sont des défis de taille à intégrer. Smartpoint, à travers ses conseils et son expertise technologique, accompagne les CIO pour transformer ces défis en opportunités.
— Yazid Nechi, Président, Smartpointt
Et demain ?
Les architectures de Reel-time data processing sont amenées a évoluer rapidement, alimentées par l’innovation technologique et les besoins accrus des entreprise pour du traitement temps réel des données. Avec l’avènement de l’IoT, l’importance de la cybersécurité devient centrale, nous amenant à adopter des protocoles plus solides et à intégrer l’IA pour une surveillance proactive. L’informatique quantique, bien que encore balbutiante, promet des avancées considérables dans le traitement de volumes massifs de données, tandis que l’apprentissage fédéré (federeted learning) met l’accent sur la confidentialité et l’efficacité de l’apprentissage automatique.
Des outils comme DataDog et BigPanda soulignent la pertinence de l’observabilité en temps réel et de l’analyse prédictive, et des plateformes telles qu’Airbyte montrent l’évolution vers des solutions de gestion de données sans code.
À mesure que ces tendances gagnent en importance, Smartpoint se prépare à un data world où l’agilité, la sécurité et la personnalisation seront les clés de voûte des infrastructures de données temps réel de demain, redéfinissant la réactivité et l’efficacité opérationnelle de tous les secteurs d’activité.
« Real-Time Data Analytics: The Next Frontier for Business Intelligence » by Thomas Erl, Zaigham Mahmood, and Ricardo Puttini
« Building Real-Time Data Applications with Azure » by Steve D. Wood
Vous vous interrogez sur quelle démarche adopter ? Quelle architecture ou quels outils choisir ? Vous avez besoin de compétences spécifiques sur vos projets ? Challengez-nous !
Les champs obligatoires sont indiqués avec *.
Architecture
Datalake VS. Datawarehouse, quelle architecture de stockage choisir ?
0 commentaires
Alors que les volumes des données collectées croient de manière exponentielle dans une variété de formats considérable, vous devez choisir comment les stocker. Devez-vous opter pour un lac de données (datalake) ou pour un entrepôt de données (datawarehouse) ? Cette décision n’est pas anodine car elle influence l’architecture globale du système d’information data, la stratégie de gestion des données et, finalement, la capacité de votre entreprises à exploiter ces données pour créer de la valeur sur vos marchés.
Un datalake, c’est comme une vaste réserve centralisée conçue pour stocker de grandes quantités de données brutes, quel que soit le format. Son principal avantage réside dans sa capacité à héberger des données non structurées, semi-structurées et structurées, offrant ainsi une flexibilité sans précédent pour l’exploration, l’analyse et l’exploitation de données via des technologies avancées comme l’IA et le machine learning.
Un datawarehouse est une solution de stockage qui organise les données en schémas structurés et hiérarchisés. Spécialement conçu pour les requêtes et les analyses avancées, il est reconnu pour ses performances, sa fiabilité, l’intégrité des données pour les opérations décisionnelles et la génération de rapports.
Le choix entre ces deux architectures de stockage n’est pas anodin. Il doit être éclairé par une fine compréhension des besoins en données de votre entreprise, de ses objectifs stratégiques, de ses processus opérationnels et de ses capacités analytiques.
1. Comprendre les datalakes et les entrepôts de données
1.1 Définition et objectifs
Un datalake est une architecture de stockage conçue pour stocker de très larges volumes de données sous leur forme brute, c’est-à-dire dans leur format natif non transformé. Contrairement aux bases de données traditionnelles, il n’impose pas de schéma au moment de l’écriture des données (schema-on-write), mais au moment de la lecture (schema-on-read), offrant ainsi une souplesse inégalée dans la manipulation et l’exploration des données. L’objectif principal d’un datalake est de centraliser les données non structurées et structurées d’une entreprise pour permettre des analyses futures très diverses, y compris l’exploration de données, le big data, le datamining, les analytics et l’intelligence artificielle.
Un entrepôt de données, ou datawarehouse, est une solution de stockage qui collecte des données en provenance de différentes sources et les transforme selon un schéma fixe, structuré et prêt à l’emploi. Il est optimisé pour assurer la rapidité et l’efficacité des requêtes et des rapports analytiques. Il est conçu pour le traitement rapide des opérations de lecture et d’écriture. L’objectif d’un entrepôt de données est de fournir une vision cohérente et unifiée des données, facilitant ainsi la prise de décision et la génération de rapports standardisés pour les fonctions opérationnelles métiers et stratégiques de l’entreprise.
1.2 Comparaison des fonctionnalités et des cas d’utilisation
Fonctionnalités des datalakes
Stockage de données à grande échelle en format brut
Capacité de stockage économique qui permet de conserver des données hétérogènes, facilitant un large éventail d’analyses exploratoires et un réservoir à explorer d’innovations futures data centric
Support de tous types de données (structurées, semi-structurées, non structurées) y compris des data tels que les logs, les flux IoT, etc.
Écosystème propice à la démocratisation de l’analyse des données, permettant aux data scientists et aux analystes de travailler avec des données non préparées ou semi-préparées
Flexibilité pour l’expérimentation avec des modèles de données évolutifs et des schémas à la volée
Intégration facile avec des outils d’analyse avancée et de machine learning
Flexibilité dans le modèle de données, qui permet des analyses exploratoires et ad-hoc
Fonctionnalités des datawarehouses
Stockage de données organisé selon un schéma défini et optimisé pour les requêtes ; avec également des outils d’ETL (Extract, Transform, Load) éprouvés pour la transformation des données
Haute performance pour les requêtes structurées et les rapports récurrents
Une source de vérité unique pour l’entreprise, facilitant la cohérence et la standardisation des métriques et des KPIs
Fiabilité et intégrité des données pour la prise de décision basée sur des données historiques consolidées
Interfaces utilisateurs conviviales pour la business intelligence, avec des capacités de reporting avancées et des visualisations interactives.
Intégration avec les systèmes de gestion de la relation client (CRM) et de planification des ressources de l’entreprise (ERP), enrichissant les données transactionnelles pour des analyses décisionnelles stratégiques
Cas d’utilisation des datalakes
Scénarios nécessitant une exploration de données pour identifier des opportunités de marchés émergents, pour prévoir des tendances de consommation ou des modèles cachés.
Environnements innovants où l’analytique en temps réel et l’intelligence opérationnelle peuvent transformer des flux de données en actions immédiates.
Projets de recherche et développement (R&D) où des données variées doivent être explorées sans la contrainte d’un schéma prédéfini.
Cas d’utilisations des datawarehouses
Dans les industries réglementées, comme les services financiers ou la santé, où l’intégrité et la traçabilité des données sont essentielles pour la conformité réglementaire.
Lorsque l’on a besoin de mener des analyses sur de longues périodes pour suivre leur évolution au fil du temps et anticiper les tendances futures. Les data warehouses offre une base solide pour les systèmes décisionnels pour les managers qui souhaitent prendre leurs décisions sur la base de données historiques détaillées.
Lorsqu’il est crucial de rapprocher des données issues de sources multiples en informations cohérentes pour piloter la stratégie d’entreprise et optimiser les processus opérationnels.
2. Avantages et Inconvénients
Avantages d’un data lake
Le data lake offre beaucoup de flexibilité pour le stockage de données. Son avantage principal réside dans sa capacité à accueillir tous types de données, des données structurées telles que les lignes et les colonnes des bases de données relationnelles, aux données non structurées comme les textes libres ou encore des médias. Ceci est un véritable avantage pour les organisations agiles qui souhaitent capitaliser sur la variété et la vitesse des données actuelles, y compris les données générées par les appareils connectés (IoT), les plateformes de médias sociaux, et autres sources numériques. L’intégration avec des plateformes d’analyses avancées et le machine learning permet d’extraire des insights précieux qui peuvent être sources d’innovation.
Avantages d’un Entrepôt de Données
L’entrepôt de données, quant à lui, est spécialement conçu pour la consolidation de données issues de divers systèmes en un format cohérent et uniforme. C’est un peu comme une bibliothèque traditionnelle où chaque livre – ou plutôt chaque donnée – a sa place attitrée, classée, indexée ! C’est une solution à privilégier pour les entreprises qui ont besoin d’effectuer des analyses complexes et récurrentes, qui exigent de la performance dans le traitement des requêtes. La structuration des données dans des schémas prédéfinis permet non seulement des interrogations rapides et précises mais assure également l’intégrité et la fiabilité des informations, ce qui est essentiel pour les rapports réglementaires, les audits et la prise de décision stratégique. Les Data warehouses sont également conçus pour interagir avec des outils de reporting et de business intelligence, offrant ainsi de la data visualisation et des analyses compréhensibles par les utilisateurs finaux.
Inconvénients, Limites et Défis
Malgré leurs nombreux avantages, les data lakes et les entrepôts de données ont chacun leurs limites ! Le data lake, de par sa nature même, peut devenir un « data swamp » si les données ne sont pas gérées et gouvernées correctement, rendant les informations difficilement exploitables. La mise en place d’une gouvernance efficace et d’un catalogue de données s’avère nécessaire pour maintenir la qualité et la questionnabilité des données.
Les data warehouses, bien que fortement structurés et performants pour les requêtes prédéfinies, peuvent être rigides en termes d’évolutivité et d’adaptabilité. L’intégration de nouvelles sources de données ou l’ajustement aux nouvelles exigences analytiques peut se révéler très coûteuse et chronophage. De plus, les entrepôts traditionnels peuvent ne pas être aussi bien adaptés à la manipulation de grands volumes de données non structurées, ce qui peut limiter leur application dans les scénarios où les formes de données sont en constante évolution.
3. Critères de choix entre un data lake et un data warehouse
3.1 Volume, Variété et Vitesse de la data
Les trois « V » de la gestion des données – volume, variété et vitesse – sont des critères essentiels dans votre choix entre un data lake et un data warehouse. Si votre organisation manipule des téraoctets ou même des pétaoctets de données diversifiées, issues de différentes sources en flux continus, un data lake est à priori le choix le plus adapté. Sa capacité à ingérer rapidement de grands volumes de données hétérogènes, voire évolutives, en fait un critère de choix déterminant dans les situations où la quantité et la multiplicité des données dictent la structure de l’infrastructure technologique.
3.2 Analyse et traitement des données
L’approche et les outils que vous utilisez pour l’analyse et le traitement des données influencent également le choix de votre architecture de stockage. Les data lakes, avec leur flexibilité et leur capacité d’ingestion de données en l’état, sont parfaitement adaptés aux environnements exploratoires où le data mining et le traitement par intelligence artificielle sont votre lot quotidien. En revanche, si vos besoins s’articulent autour d’analyses structurées et de reporting périodique, un data warehouse offre un environnement hautement performant optimisé pour ces activités, avec la possibilité d’extraire les données de manière rapide et fiable.
3.3 Gouvernance, sécurité et conformité
La manière dont vous gérez la gouvernance, la sécurité et la conformité des données est un facteur déterminant. Les data warehouses, avec leurs schémas de données structurés et leur maturité en matière de gestion de la qualité des données, offrent un cadre plus strict et sécurisé, ce qui est impératif dans les environnements réglementés. Les data lakes requièrent quant-à-eux une attention particulière en matière de gouvernance et de sécurité des données, surtout parce qu’ils stockent des informations à l’état brut, qui pourraient inclure des données sensibles ou personnelles.
3.4 Coûts et complexité de mise en oeuvre
Enfin, les considérations financières et la complexité de la mise en œuvre sont des critères déterminants. Mettre en place un data lake est souvent moinscoûteux en termes de stockage brut, mais nécessite souvent des investissements significatifs additifs en outils et en compétences pour être en capacités d’exploiter pleinement cet environnement. Les data warehouses, en revanche, générèrent souvent des coûts initiaux plus élevés, mais leur utilisation est souvent plus rapide et moins complexe, avec un ensemble d’outils déjà intégrés pour la gestion et l’analyse des données.
4. Architecture et technologies : Data Lakes vs. Data Warehouses
L’architecture et les technologies des data lakes et des data warehouses révèlent des différences essentielles dans la manière dont les données sont stockées, gérées, et exploitées. Ces différences influencent directement le choix entre ces deux solutions en fonction des besoins spécifiques en matière de données.
4.1. Stockage de Données
Data Lakes : Les data lakes sont conçus pour stocker d’énormes volumes de données sous leur forme brute, sans nécessiter de schéma prédéfini pour le stockage. Cela permet une grande flexibilité dans le type de données stockées, qu’elles soient structurées, semi-structurées ou non structurées. Les technologies comme Apache Hadoop et les services cloud comme Amazon S3 sont souvent utilisés en raison leur évolutivité et leurs capacités à gérer de très larges volumes.
Data Warehouses : À l’inverse, les data warehouses stockent des données qui ont été préalablement traitées (ETL – Extract, transform & load) et structurées selon un schéma prédéfini, ce qui facilite les requêtes complexes et l’analyse de données. Des solutions comme Amazon Redshift, Google BigQuery, et Snowflake sont reconnues pour leur efficacité dans le stockage et la gestion de données structurées à grande échelle.
4.2. Indexation et Optimisation des Requêtes
Data Lakes : L’indexation dans les data lakes peut être plus complexe en raison de de l’hétérogénéité des formats de données. Cependant, des outils comme Apache Lucene ou Elasticsearch peuvent être intégrés pour améliorer la recherche et l’analyse des données non structurées. Les data lakes requièrent souvent un traitement supplémentaire pour optimiser les requêtes.
Data Warehouses : Les data warehouses bénéficient d’une indexation et d’une optimisation des requêtes plus avancées dès le départ, grâce à leur structure hautement organisée. Des techniques comme le partitionnement des données et le stockage en colonnes (par exemple, dans Amazon Redshift) permettent d’exécuter des analyses complexes et des requêtes à haute performance de manière plus efficace.
4.3. Technologies et outils éditeurs
Différents éditeurs et technologies offrent des solutions spécialisées pour les data lakes et les data warehouse :
Pour les Data Lakes :
Apache Hadoop : Écosystème open-source qui permet le stockage et le traitement de grandes quantités de données.
Amazon S3 : Service de stockage objet offrant une scalabilité, une disponibilité et une sécurité des données.
Microsoft Azure Data Lake Storage : Solution de stockage haute performance pour les data lakes sur Azure.
Pour les Data Warehouses
Snowflake : Infrastructure de données cloud offrant une séparation du stockage et du calcul pour une élasticité et une performance optimisée.
Google BigQuery : Entrepôt de données serverless, hautement scalable, et basé sur le cloud.
Oracle Exadata : Solution conçue pour offrir performance et fiabilité pour les applications de bases de données critiques.
Databricks, le pont entre Data Lakes et Data Warehouses
Databricks a un rôle crucial dans l’évolution des architectures de données en offrant une solution qui réduit la frontière entre les data lakes et les data warehouses. Par son approche lakehouse, Databricks permet aux organisations de gérer leurs données de manière plus efficace, en facilitant à la fois le stockage de grandes quantités de données brutes et l’analyse avancée de ces données.
Plateforme Unifiée : Databricks offre une plateforme basée sur Apache Spark qui permet aux utilisateurs de réaliser des tâches d’ingénierie de données, de science des données, de machine learning, et d’analyse de données sur un même environnement. Cette approche intégrée facilite la collaboration entre les équipes et optimise le traitement des données.
Data Lakehouse : Databricks promeut le concept de « Lakehouse », un modèle d’architecture qui combine les avantages des data lakes et des data warehouses. Le lakehouse vise à fournir la flexibilité et la capacité de stockage des data lakes pour des données brutes et diversifiées, tout en offrant les capacités d’analyse et de gestion de la qualité des données typiques des data warehouses.
Delta Lake : La technologie proposée par Databricks est Delta Lake, un format de stockage qui apporte des fonctionnalités transactionnelles, de gestion de la qualité des données, et d’optimisation des requêtes aux data lakes. Delta Lake permet aux organisations de construire un data lakehouse, en rendant les data lakes plus fiables et performants pour des analyses complexes.
Avantages en architectures Data : En utilisant Databricks, les entreprises peuvent tirer parti de la scalabilité et de la flexibilité des data lakes tout en bénéficiant des performances et de la fiabilité des data warehouses. Cette approche permet d’effectuer des analyses avancées, du traitement de données en temps réel, et du machine learning à grande échelle.
Intégration avec les Écosystèmes de Données Existantes : Databricks s’intègre facilement avec d’autres plateformes de données, comme les services de stockage cloud (Amazon S3, Azure Data Lake Storage, Google Cloud Storage) et les solutions de data warehouse (Snowflake, Google BigQuery, etc.), offrant ainsi une grande flexibilité dans la conception de l’architecture de données.
5. Cas pratiques et scénarios d’utilisation par secteur
5.1 Cas d’utilisation d’un Data Lake
Géants du web : Les entreprises de la tech utilisent des data lakes pour analyser d’importants volumes de données utilisateurs afin d’affiner les algorithmes de recommandation, de personnaliser l’expérience client et d’optimiser les stratégies de contenu et de publicité.
Industries : Les data lakes permettent de collecter et d’analyser les données issues des capteurs IoT pour la surveillance en temps réel des équipements, l’optimisation des chaînes logistiques, et la prévision des opérations de maintenance.
Transport : Les entreprises du secteur automobile exploitent des data lakes pour traiter de grandes quantités de données issues de tests de véhicules et ou encore celles relatives aux véhicules autonomes et à l’analyse des comportements de conduite.
5.2 Cas d’utilisation d’un Entrepôt de Données
Finance et banque : Les institutions financières et bancaires s’appuient sur des data warehouses pour effectuer des analyses de marché, générer des rapports de performance financière, et conduire des analyses de risques basées sur des données historiques.
Retail: Les entreprises de retail utilisent des data warehouses pour analyser les tendances d’achat et de consommation sur plusieurs années, permettant une gestion des stocks plus précise et le développement de campagnes marketing ciblées.
Énergie : Les sociétés du secteur de l’énergie exploitent des data warehouses pour la gestion des données relatives à la production, à la consommation énergétique, et pour se conformer aux régulations environnementales et leur exigences en termes de reporting.
5.3 Synthèse des meilleures pratiques
Une mise en œuvre réussie des data lakes et des data warehouses dépend de la stratégie qui va orienter votre choix d’architecture de données.
Pour les Data Lakes
Gouvernance rigoureuse : Instaurez un cadre strict de gouvernance pour maintenir l’intégrité des données et clarifier l’accès et l’utilisation des données.
Qualité : Intégrez des processus systématiques pour le nettoyage et la validation des données, garantissant leur fiabilité pour l’analyse et la prise de décision dans la durée.
Catalogage : Adoptez des solutions de Data Catalog pour faciliter la recherche et l’utilisation des données stockées, transformant le data lake en un réservoir de connaissances exploitables.
Pour les Data Warehouses
Maintenance proactive : Menez des audits réguliers pour préserver les performances et adapter la structure aux besoins évolutifs de l’entreprise.
Évolution : Faites évoluer votre écosystème data avec prudence, en intégrant des innovations technologiques pour améliorer les capacités analytiques et opérationnelles.
Compétences à: Investissez dans la formation des équipes pour qu’elles restent à la pointe de la technologie et puissent tirer le meilleur parti de l’infrastructure de données.
Le débat entre data lake et data warehouse ne se réduit pas à un simple choix technologique ; il s’agit d’une décision stratégique qui reflète la vision, la culture et les objectifs de votre entreprise en matière de création de valeur à partir de l’exploitation des données. Alors qu’un data lake offre une palette vaste et flexible pour l’agrégation de données brutes propices à l’exploration et à l’innovation analytique ; un data warehouse apporte une structure organisée et performante pour le reporting et les analyses décisionnelles.
Votre choix dépend en somme des objectifs spécifiques de votre entreprise, des exigences en matière de gouvernance des données, de la variété et du volume des données, ainsi que de la rapidité avec laquelle l’information doit être convertie en action. Le data lake convient aux organisations qui aspirent à une exploration de données libre et sans contrainte, où les potentiels de l’IA et du machine learning peuvent être pleinement exploités. Inversement, le data warehouse est la solution pour ceux qui cherchent à solidifier leur Business Intelligence avec des données cohérentes et fiables.
Les data lakes et data warehouses ne sont pas mutuellement exclusifs et peuvent tout à fait coexister, se complétant mutuellement au sein d’une architecture de données bien conçue, permettant ainsi aux organisations de tirer le meilleur parti des deux mondes.
Stack technologique
Stratégies d’ingestion de la data et solutions 2024
0 commentaires
Votre stratégie d’ingestion de données dépend aussi de votre architecture data et de vos choix en matière de stockage. La maîtrise des différentes stratégies d’ingestion des données essentielle dans l’ingénierie data. C’est un prérequis pour garantir l’efficacité, la fiabilité et la scalabilité des pipelines de données.
L’importance de l’ingestion de données
L’ingestion de données est le premier contact entre la donnée brute et les systèmes d’information. Elle pose les bases des analyses futures et de la création de valeur.
Cette étape est intrinsèquement liée à l’architecture globale de traitement des données et aux choix de stockage, qui doivent être adaptés pour répondre aux différents cas d’usages.
Les stratégies d’ingestion de données
Le choix de la stratégie d’ingestion dépend de plusieurs facteurs, comme que le volume des données, la vitesse requise pour l’obtention des insights, la complexité des opérations de transformation, et le niveau de latence acceptable. L’intégration des stratégies d’ingestion dans l’architecture de données et les choix de stockage permet de créer des pipelines robustes, efficaces et créateurs de valeur pour votre entreprise.
1. ETL (Extract, Transform, Load)
L’ETL est la méthode traditionnelle. Les données sont extraites de différentes sources puis transformées pour répondre aux exigences de l’entrepôt de données (nettoyage, agrégation, résumé, etc.). Elle sont ensuite chargées dans le data warehouse. Cette approche est à privilégier lorsque la transformation des données nécessite des calculs lourds qui sont non seulement couteux en ressources informatiques ; mais aussi sont plus efficaces lorsqu’ils sont effectués en dehors de la base de données cible.
L’ELT est une variante de l’ETL. Les données sont d’abord extraites puis chargées dans la destination cible (souvent un data lake ou un entrepôt de données moderne). La transformation est effectuée à postériori. Cette stratégie tire parti de la puissance de calcul des systèmes de stockage modernes pour effectuer les différents traitements. L’ELT est à privilégier dans les environnements qui nécessitent une grande flexibilité et une exploration rapide des données, ainsi que pour les architectures big data.
Le Reverse ETL est une approche relativement nouvelle qui consiste à prendre des données déjà transformées et organisées dans un data warehouse ou un data lake, et à les envoyer vers des systèmes opérationnels comme les CRM ou les plateformes de marketing automatisé. Cette stratégie est utilisée pour enrichir les applications opérationnelles avec des insights approfondis et favoriser ainsi des actions en temps réel basées sur des analyses de données.
L’ingestion de données en streaming est une approche où les données sont ingérées en temps réel à mesure qu’elles sont générées. Cette stratégie est essentielle pour les cas d’utilisation qui dépendent de la fraîcheur des données et le traitement en continu des flux, comme la détection des fraudes, la surveillance en temps réel de systèmes (IOT) ou les recommandations instantanées.
La fédération de données est une approche où les données restent dans leurs systèmes sources et sont virtualisées pour apparaître comme source de données unique. Cette stratégie évite le déplacement physique des données et est utile pour les requêtes ad hoc ou des cas d’utilisation d’accès aux données en temps réel. Elle est supportée par des frameworks comme Hadoop.
6. Change Data Capture (CDC)
Le Change Data Capture est une technique utilisée pour capturer les changements dans les données à leur source et les répliquer dans le système de destination. Le CDC est souvent utilisé pour synchroniser des bases de données en temps réel et pour garantir que les entrepôts de données et les data lakes sont constamment mis à jour avec les dernières informations.
Quelques solutions recommandées par nos équipes : Informatica ou Talend
Stratégies d’ingestion et architectures de données
La stratégie d’ingestion choisie doit être cohérente avec votre architecture data et s’aligner avec les besoins analytiques et opérationnels de votre entreprise.
Les architectures data warehouses sont à privilégier pour des besoins d’analyse et de reporting structuré qui requièrent des données bien organisées et souvent transformées avant la phase ingestion.
Les data lakes offrent davantage de flexibilité pour les données non structurées ou semi-structurées et supportent à la fois les ingestions en temps réel et par lots, permettant ainsi un traitement et une analyse à postériori.
Les architectures en streaming répondent au besoin d’analyses en temps réel car elles gèrent l’ingestion en continu des données via des plateformes spécialisées comme Apache Kafka.
Les architectures microservices et orientées événements sont décentralisées et offrent davantage de scalabilité, chaque microservice gérant son propre pipeline de données.
Les architectures hybrides mixent entrepôts et lacs de données pour capitaliser sur les avantages de chaque approche.
Options de stockage et leur impact sur l’ingestion
Les choix de stockage, comme le stockage sur disque, le stockage objet dans le cloud ou les bases de données NoSQL, influencent directement la manière dont les données sont ingérées et gérées.
Le stockage sur disque est à privilégier pour un accès rapide et fréquent.
Le stockage objet dans le cloud permet plus de scalabilité pour les data lakes avec des capacités d’intégration avec des services d’analyse dans le cloud.
Le stockage en bloc soutient les performances en lecture/écriture pour les bases de données particulièrement exigeantes.
Le stockage de fichiers distribués est optimal pour l’accès sur plusieurs serveurs.
Les bases de données NoSQL sont à privilégier les données non structurées car elles offrent davantage de flexibilité avec les données non structurées.
Pour conclure ?
L’ingestion de données est indissociable de l’architecture de données et des solutions de stockage choisies. Nos data engineers Smartpoint appréhendent cela comme un écosystème interconnecté, optimisé pour les besoins spécifiques de votre organisation. En prenant en considération tous ces critères – cas d’utilisation, fiabilité, destination des données, fréquence d’accès, volume, format, qualité et gestion des données en streaming – ils sont en capacité de construire des bases solides pour la gestion des données qui vous permettront de tirer des insights précieux et d’alimenter vos prises de décision.
Vous avez besoin d’être accompagné dans votre stratégie d’ingestion de données ? Vous avez besoin d’être conseillé pour trouver la solution qui vouscorrespond ? Vous avez besoin de renfort dans vos équipes ou un chantier à lancer ? Challengez-nous !