Phénomène

Terminé le temps où l’ingénieur data se concentrait sur la modélisation de données et passait l’essentiel de son temps en transformations ETL !
Des générations d’ingénieurs data se sont épuisées à mettre en œuvre les meilleures pratiques de modélisation de données (modèle conceptuel, logique et physique) segmentés par domaines, sous-domaines puis interconnectés entre eux. Il existe encore plusieurs types modélisation de données : modèle de données hiérarchique, en réseau, relationnel, orienté objet pour les plus traditionnels mais aussi modèle de données entité-relation, dimensionnel ou encore orienté graphe.
Ne nous y trompons pas, la modélisation de données, est toujours bel et bien indispensable en BI & Analytics avancées. Mais le rôle d’ingénieur data a beaucoup évolué ces dernières années et ce n’est que le commencement ! Il est beaucoup moins focus sur la modélisation de données, il se concentre davantage sur les capacités à déplacer les données et s’appuie sur de nouvelles approches pour traiter les données.
L’approche Data Lake couplée avec un processus d’ELT
La différence ? On ne sélectionne plus les données que l’on considère utiles à stocker mais on les déverse dans le lac de données pour qu’elles soient accessibles pour le reste de l’organisation, quand ils auront besoin. Dans les faits, on n’a plus besoin de transformer les données. Les Data Scientists peuvent ainsi accéder aux données brutes (sans avoir besoin de faire appel à un ingénieur data) et effectuer eux-mêmes les transformations qu’ils souhaitent. Ainsi, en fonction de la complexité des données et des compétences (et l’autonomie) de ceux qui vont les consommer, les ingénieurs n’ont finalement plus besoin de passer beaucoup de temps sur les phases de modélisation.
Le cloud avec ses bibliothèques de connecteurs et l’automatisation
Le cloud a contribué également à minimiser les pratiques de modélisation au préalable des données. Le Move-to-the-cloud massif de solutions autrefois sur site, a poussé les ingénieurs data à se concentrer sur la migration des données en utilisant notamment des outils en SaaS comme Fivetran ou Stich qui proposent des Datasets pre-modélisés pour de larges scénarios d’intégration.
Le Machine Learning
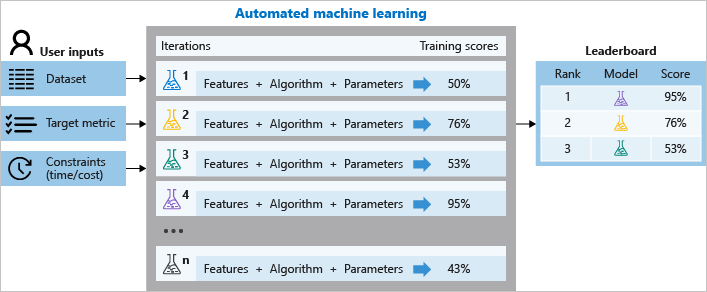
La montée en puissance du ML et surtout du développement AutoML ont aussi contribué à transformer les ingénieurs data en « Data Movers ».
Le streaming de données et le traitement temps réel
Certes, il est toujours possible d’effectuer des agrégations sur des flux (via Spark par exemple). Mais dans la réalité, la plupart des traitements effectués sur les flux tendent à se concentrer sur le filtrage des données (triggers) et leur enrichissement … et non plus leur modélisation. De plus, les exigences accrues de traitement en temps réel éloignent les phases initiales de transformation des données vers l’application centrale (Core).
Cependant, la modélisation des données (Data Modeling) reste incontournable dans de nombreux cas d’usages en data warehousing et BI mais aussi pour être en capacités de mener des analyses avancées en temps réel via les techniques de modélisation dimensionnelle (architecture Lambda).
En effet, rien ne vaut la modélisation des données pour comprendre vraiment comment fonctionnent les données, comment les exploiter au mieux. La modélisation offre aussi des capacités de découverte et d’interprétation inégalées.
De plus, les techniques de modélisation évoluent, les systèmes convergent !
Des outils comme Dbt permettent aujourd’hui d’orchestrer des séries de transformations.
L’introduction de la jointure flux-flux permet de gérer les mises à jour dimensionnelles et réduit la nécessité d’utiliser des modèles de réconciliation. Les bases de données en continu vont encore plus loin en faisant des flux de données en temps réel une partie intégrante du modèle de données. Cette architecture « Kappa » permet une approche simplifiée pour exploiter les données en temps réel.
Avec l’arrivée de solutions de bases de données MPP (comme Snowflake), les différences entre data lake, data warehouse et data lake house sont de plus en plus floues… et quoi qu’ils en soient, elles convergent (même si elles ne couvrent pas encore toutes les fonctionnées des entrepôts de données) pour faciliter certains cas de modélisation de données.
En somme, le data modeling a encore de beaux jours devant lui ! Et le rôle de l’ingénieur data n’a pas fini de se transformer.
Sources :
Les 7 modèles de données les plus utilisés aujourd’hui en entreprises : https://www.lemagit.fr/conseil/Les-sept-modeles-de-donnees-les-plus-utilises-en-entreprise
The lost art of data modeling : https://medium.com/analytics-and-data/the-lost-art-of-data-modeling-1118e88d9d7a