Notre score nous place dans le 10% des entreprises françaises les plus engagées en ce domaine.
Chez Smartpoint, nous sommes une entreprise engagée et nous sommes particulièrement sensibles aux enjeux climatiques. Nous militons également pour un numérique plus responsable et nous nous mobilisons pour réduire l’empreinte environnementale de la Tech sein de la communauté Planet Tech’Care.
Smartpoint poursuit son engagement et réalise son premier bilan de ses émissions carbone avec Greenly selon une méthodologie standardisée par l’ADEME sur les scopes 1, 2 et 3.
Avec un bilan de 3,5 tonnes de CO2 par collaborateur, nous sommes déjà bien en dessous de la moyenne de notre secteur d’activité (Agence de création digitale et ESN) qui se situe à 7,6 tonnes de CO2 par collaborateur. C’est mieux mais pas suffisant pour Smartpoint, nous sommes collectivement déterminés et nous souhaitons aller plus loin !
Nous allons mettre en place un ensemble d’actions et de mesures qui vont nous permettre de limiter encore davantage notre impact et contribuer à limiter le réchauffement climatique.
Innovations Data vs. Sobriété numérique ? Oui, c’est possible.
0 commentaires
Comment contribuer au plan de sobriété énergétique présenté par le gouvernement début octobre ? Chez Smartpoint, on s’engage et on conseille nos clients car c’est une démarche qui s’applique à toutes les phases de votre projet : cadrage, conception, design d’architecture, développement, choix de solutions et de technologies, hébergement, etc.
Rappelons que le numérique, c’est 10% de la consommation électrique française et 2% de l’empreinte carbone au niveau national (selon les études de l’Ademe, Agence de la transition écologique et l’Arcep), émissions qui pourraient atteindre les 7% d’ici 2040. Au niveau mondial, les datacenters représentent 1% de la consommation électrique et en France (rapport du Sénat en 2020) ils représentaient déjà 14% de l’empreinte carbone du numérique en 2019 ! Il est temps d’agir concrètement car – et c’est bien le paradoxe – notre monde de plus en plus digitalisé consomme toujours plus de matières et génère toujours plus de pollution numérique.
Concrètement, voici nos conseils pour repenser vos projets data en adoptant une démarche plus responsable et moins énergivore.
Rationaliser le stockage de la data en ne stockant que les données vraiment utiles, éviter la duplication des données et mettre en place un processus automatisé de gestion du cycle de vie des données pour supprimer celles qui ne sont plus nécessaires (et lutter ainsi contre le DataSwamp)
Couper les serveurs non utilisés et en profiter pour passer aux greens data centers (norme Energy Star par exemple) qui ont une plus faible consommation énergétique
Regarder où les serveurs de votre Cloud Provider sont implantés car la source d’énergie locale utilisée diffère. Un data center en France est alimenté par l’énergie dé-carbonée du nucléaire … et non issue d’usines à charbon !
Adopter les serveurs virtuels qui ne fonctionnent que lorsqu’on les sollicite ou choisir des serveurs mutualisés
Réfléchir à la consommation énergétique additionnelle que l’introduction d’une nouvelle technologie va induire avant de l’adopter. Par exemple, avons-nous vraiment besoin de traitement temps réel dans tel ou tel projet data quand on connait la consommation de ce type de fonctionnement ? Avons-nous besoin de lancer autant de requêtes à cette fréquence ?
Adopter l’écoconception dès la phase de design de votre projet car on sait qu’au final près d’1/3 des fonctionnalités demandées par les métiers … ne seront finalement pas utilisées ou n’étaient pas vraiment nécessaires ! A suivre d’ailleurs l’initiative très intéressante de APIDAYS en ce domaine. .
Engager une démarche de normalisation ISO 25010 ou ISO 5055:2021 qui encadre la qualité logicielle et donne des orientations pour améliorer une conception plus « sobre » du code
Optimiser l’architecture technique de vos applications
Décommissionner ou initier le refactoring de vos applications Legacy devenues ingérables et extrêmement énergivores en termes de fonctionnement suite au rajout successifs de « couches » année après année
Penser à la réusabilité de vos composants et à la maintenabilité dans le temps en adoptant par exemple une architecture micro-services
sobriété écologique et transformation numérique
Phénomène
Tendances Tech au top en cette rentrée 2022
0 commentaires
Les technologies sont les catalyseurs d’un monde qui change. Elles contribuent à l’amélioration de la productivité des entreprises mais pas que ! Elles permettent d’inventer et de réinventer des offres, de participer à un meilleur bien-être de l’humanité, d’innover pour repenser nos manières de vivre …
Nous partageons cette étude très intéressante menée par Mc Kinsey qui donne des perspectives sur comment ces tendances technologiques pourraient s’appliquer à votre organisation.
L’intelligence artificielle est entrée dans sa phase d’applications concrètes : résolution de problèmes, prédictions, lancement d’actions automatisées en fonction des phénomènes, offres augmentées, meilleures prises de décisions.
Toujours plus de connectivité avec les technologies 5G/6G, les réseaux wireless à faible puissance, les satellites en orbite et autres technologies qui prennent en charge une multitude de solutions numériques susceptibles de stimuler la croissance et la productivité dans tous les secteurs.
La bio-ingénierie. La convergence des technologies biologiques et IT contribue à améliorer la santé et les performances humaines, transforme les chaînes de valeur alimentaire et crée une multitude de nouveaux produits et de services innovants.
Une énergie plus propre ! De nouvelles solutions plus propres et plus responsables vont voir le jour. Cela va bouleverser nos métiers, ne serait-ce que dans la manière de collecter, de traiter et de stocker les data que nous produisons et consommons de manière exponentielle. Il était temps ! Chez Smartpoint, nous prônons cette approche smart data depuis notre création dont la lutte contre le data swamp.
De nouvelles solutions de mobilité vont apparaitre aussi pour un transport des personnes et des marchandises plus efficace, optimisé et surtout durable.
La technologie va aussi participer à transformer la consommation industrielle et individuelle pour faire face aux enjeux environnementaux dont le changement climatique.
L’avènement du Web 3 basé sur des plateformes et des applications qui permettent d’évoluer vers un futur d’Internet décentralisé avec des normes et des protocoles ouverts, tout en protégeant les droits de propriété numérique, en offrant aux utilisateurs une plus grande propriété de leurs données et en catalysant de nouveaux modèles économiques.
Industrialisation du Machine Learning avec des solutions logicielles et matérielles désormais matures pour accélérer le développement et le déploiement du ML et pour soutenir le pilotage des performances, la stabilité et l’amélioration continue.
Technologies de réalité immersive qui utilisent des technologies de détection et l’informatique spatiale pour aider les utilisateurs à « voir le monde différemment » grâce à la réalité mixte ou augmentée ou encore à « voir un monde différent » grâce à la réalité virtuelle.
Le cloud et l’edge computing vont continuer à se déployer. Concrètement, cela consiste à répartir les charges de travail informatiques entre des centres de données distants et des nœuds locaux afin d’améliorer la souveraineté des données, l’autonomie, la productivité des ressources, la latence et la sécurité.
L’avénement d’architectures de confiance numérique qui vont permettre aux organisations d’instaurer, de développer et de préserver une relation de confiance entre chaque partie prenante dans l’utilisation des données et l’usage des produits et autres services numériques.
Suite aux progrès réalisés dans les technologies spatiales, la réduction des couts des satellites, des lanceurs et des capacités d’habitations, on va assister à une nouvelle génération d’opérations et la naissance de services spatiaux innovants.
Les technologies quantiques devraient permettre une augmentation exponentielle des performances de calcul et la résolution de problématiques inédites. Elles devraient permettre de transformer les réseaux en les rendant plus sûrs.
L’avènement d’une nouvelle génération de logiciels qui s’appuient sur un développement et des tests assistés par l’intelligence artificielle et les plateformes low code ou non code.
Larges volumes et complexité croissante des données, quelle data dream team mettre en place.
0 commentaires
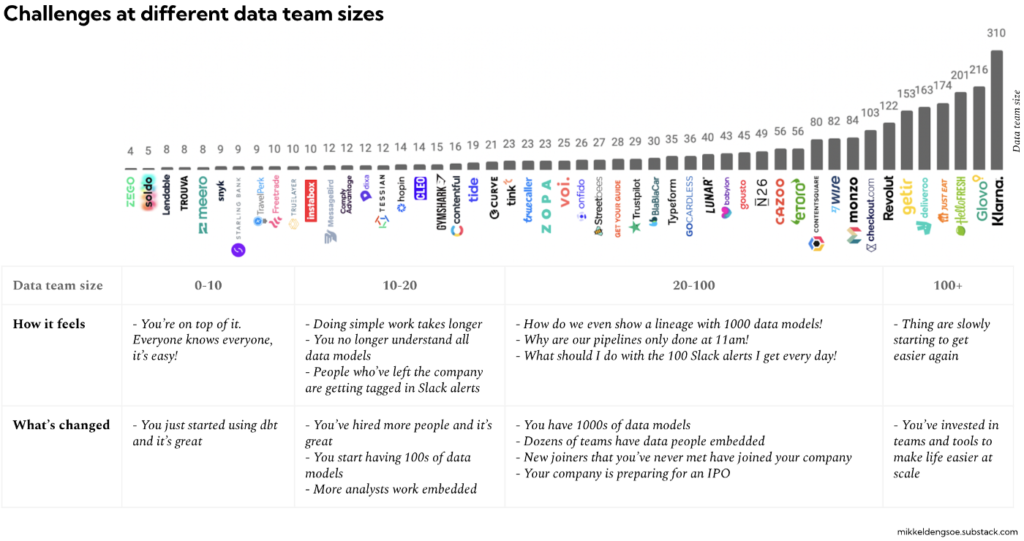
On constate que la taille des équipes Data au sein des organisations ne cesse de croitre, comme si elle était proportionnelle à la complexité et au volume croissant des données à exploiter.
Sur le papier, cela peut sembler cohérent car, à l’échelle, les données sont en effet plus complexes. Affecter plus de ressources dédiées, c’est plus d’informations collectées, plus d’analyses, plus de modèles de ML, plus de données restituées pour mieux piloter ou enrichir vos applicatifs.
Mais cela génère aussi plus de complexité, de dépendances, d’exigences mais aussi d’incohérences et de nouveaux problèmes !
L’impact de la taille des équipes data sur l’efficacité
Une petite équipe, c’est des ressources plus limitées mais cela a l’avantage de faciliter les choses ! Tout le monde se connait et appréhende les compétences de chacun. Il est plus facile de mettre en place une méthode de travail et de l’appliquer. Chacun maîtrise la data stack utilisée et si il y a un dysfonctionnement quelque part, c’est relativement rapide de l’identifier et de le régler.
Au-delà de 10 personnes au sein de l’équipe data, cela se complique ! On commence à avoir des doutes sur la fiabilité des données qu’on utilise, le data lineage (traçabilité des données / data catalog) commence à être trop important pour avoir encore du sens … et les sources d’insatisfactions chez les utilisateurs métiers se multiplient.
Sur des très grosses équipes, cela devient critique ! Nous voyons cela chez nos clients où on dépasse désormais souvent 50 collaborateurs ! Personne ne se connait vraiment, il y a eu du turn-over inéluctable, on ne maîtrise plus vraiment la data stack car chacun y a contribué sans vraiment prendre le temps de documenter quoi que ce soit ni de comprendre l’historique. Les initiatives individuelles se sont multipliées pour satisfaire ponctuellement des besoins utilisateurs plus critiques que d’autres. Cela a généré du coding spécifique, difficile à maintenir et encore moins à faire évoluer dans la durée. Le Daily pipeline se termine beaucoup trop tard pour avoir encore du sens.
On arrive à un résultat exactement à l’opposé des attentes. Et cela s’explique :
Le processus permettant la traçabilité des données (data lineage) qui consiste à créer une sorte de cartographie pour recenser l’origine des données, les différentes étapes de transformation et pourquoi elles ont été mis en place ainsi que les différentes évolutions dans la durée … devient ingérable. Pourtant, la visualisation de toute cette arborescence est indispensable pour comprendre toutes les dépendances entre les données et comment elles circulent effectivement. Dès lors qu’on franchit des centaines de modèles de données, le data lineage perd toute son utilité. A cette échelle, il devient impossible de comprendre la logique ni de localiser les goulots d’étranglement.
Résultat, le pipeline de données fonctionne de plus en plus lentement, il se dégrade inexorablement car il y a trop de dépendances sans compter qu’il y a forcément quelqu’un qui a essayé de colmater des joints quelque part 😉 Et cela a des conséquences : le fameux retour du plat de spaghettis ! Résultats : les données ne sont jamais prêtes dans les temps.
Les Data Alerts deviennent votre quotidien et vous passez désormais votre temps à essayer de les résoudre sans compter qu’il est difficile de savoir à qui incombe la résolution du problème à la base !
En conclusion.
Votre capacité à exploiter vos données convenablement, même si elles sont de plus en plus volumineuses et complexes, se résume finalement à des enjeux d’ordre davantage organisationnels que techniques. Même si, à ce stade, une véritable solution de Data Catalog s’impose tout de même !
A l’échelle, vous devez composer avec des équipes hybrides qui ont du mal à intégrer comment votre data stack fonctionne. C’est un état de fait contre lequel il est difficile de lutter. Une des solutions consiste à diviser votre team data en plusieurs petites équipes qui seront en charge d’une pile technologique en particulier qu’ils devront pour le coup bien maîtriser, documenter et transmettre lors de l’onboarding de nouvelles équipes : ceux en charge de l’exploration ou de la collecte, ceux en charge de l’analyse, ceux en charge d’optimiser les performances du pipeline, ceux en charge de l’amélioration de l’architecture globale, etc.
C’est notamment pour ces raisons que chez Smartpoint, nous vous proposons d’intervenir en apportant des compétences très pointues : Architectes data, ingénieurs data, data analysts, etc. Nous sommes également une ESN spécialisée en Data avec les capacités de mobiliser en volume des équipes Data qui ont l’habitude de travailler ensemble, selon une méthodologie de travail commune et cela change tout.
Le nouvel ensemble propose désormais deux pôles d’expertises majeurs en Data et Développement de produits.
Paris, le 10 juin 2022
Smartpoint, pure player de la Data, annonce le rapprochement avec Captiva, ESN parisienne de près de 80 collaborateurs, spécialisée dans le développement de produits et la qualité logicielle.
Désormais, le groupe Smartpoint, c’est une proposition de valeur élargie en expertises technologiques autour des deux principaux chantiers des entreprises en France pour soutenir leur transformation digitale : l’exploitation de la data et sa valorisation ; ainsi que le développement de nouveaux produits.
Le nouvel ensemble compte plus 250 collaborateurs qui réalisent des prestations IT ou délivrent des projets au forfait pour des entreprises des secteurs de la banque-assurance, la grande distribution, le transport, l’énergie, les média et les services.
Conformément à notre plan de croissance, nous cherchions à nous développer en nous rapprochant d’entreprises qui nous ressemblent en termes de valeurs et de vision. C’est chose faite avec Captiva et ses 80 collaborateurs, qui rejoignent l’aventure et vont désormais partager nos ambitions. Captiva est spécialisée en développement applicatif, testing et AMOA. En termes de références clients, pour ne citer que quelques comptes, Captiva intervient aujourd’hui au sein du Groupe Crédit Agricole, Accor Hotels et Manpower. Nous sommes donc très complémentaires et ce rapprochement va nous permettre d’avoir une position plus forte sur notre marché.
Yazid Nechi, Président de Smartpoint
Phénomène
Du Data Modeling … à « déménageur » de données, quel est le rôle de l’ingénieur data aujourd’hui ?
0 commentaires
Terminé le temps où l’ingénieur data se concentrait sur la modélisation de données et passait l’essentiel de son temps en transformations ETL !
Des générations d’ingénieurs data se sont épuisées à mettre en œuvre les meilleures pratiques de modélisation de données (modèle conceptuel, logique et physique) segmentés par domaines, sous-domaines puis interconnectés entre eux. Il existe encore plusieurs types modélisation de données : modèle de données hiérarchique, en réseau, relationnel, orienté objet pour les plus traditionnels mais aussi modèle de données entité-relation, dimensionnel ou encore orienté graphe.
Ne nous y trompons pas, la modélisation de données, est toujours bel et bien indispensable en BI & Analytics avancées. Mais le rôle d’ingénieur data a beaucoup évolué ces dernières années et ce n’est que le commencement ! Il est beaucoup moins focus sur la modélisation de données, il se concentre davantage sur les capacités à déplacer les données et s’appuie sur de nouvelles approches pour traiter les données.
L’approche Data Lake couplée avec un processus d’ELT
La différence ? On ne sélectionne plus les données que l’on considère utiles à stocker mais on les déverse dans le lac de données pour qu’elles soient accessibles pour le reste de l’organisation, quand ils auront besoin. Dans les faits, on n’a plus besoin de transformer les données. Les Data Scientists peuvent ainsi accéder aux données brutes (sans avoir besoin de faire appel à un ingénieur data) et effectuer eux-mêmes les transformations qu’ils souhaitent. Ainsi, en fonction de la complexité des données et des compétences (et l’autonomie) de ceux qui vont les consommer, les ingénieurs n’ont finalement plus besoin de passer beaucoup de temps sur les phases de modélisation.
Le cloud avec ses bibliothèques de connecteurs et l’automatisation
Le cloud a contribué également à minimiser les pratiques de modélisation au préalable des données. Le Move-to-the-cloud massif de solutions autrefois sur site, a poussé les ingénieurs data à se concentrer sur la migration des données en utilisant notamment des outils en SaaS comme Fivetran ou Stich qui proposent des Datasets pre-modélisés pour de larges scénarios d’intégration.
Le Machine Learning
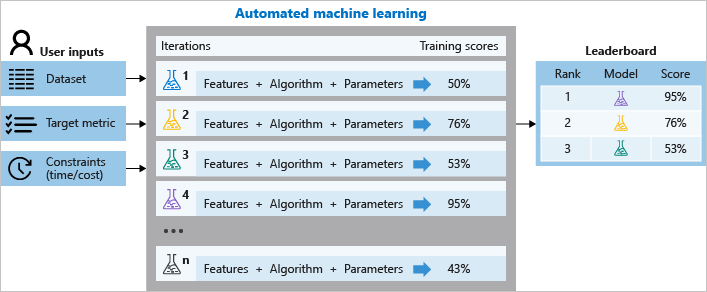
La montée en puissance du ML et surtout du développement AutoML ont aussi contribué à transformer les ingénieurs data en « Data Movers ».
Source Microsoft / 05/2022
Le streaming de données et le traitement temps réel
Certes, il est toujours possible d’effectuer des agrégations sur des flux (via Spark par exemple). Mais dans la réalité, la plupart des traitements effectués sur les flux tendent à se concentrer sur le filtrage des données (triggers) et leur enrichissement … et non plus leur modélisation. De plus, les exigences accrues de traitement en temps réel éloignent les phases initiales de transformation des données vers l’application centrale (Core).
Cependant, la modélisation des données (Data Modeling) reste incontournable dans de nombreux cas d’usages en data warehousing et BI mais aussi pour être en capacités de mener des analyses avancées en temps réel via les techniques de modélisation dimensionnelle (architecture Lambda).
En effet, rien ne vaut la modélisation des données pour comprendre vraiment comment fonctionnent les données, comment les exploiter au mieux. La modélisation offre aussi des capacités de découverte et d’interprétation inégalées. De plus, les techniques de modélisation évoluent, les systèmes convergent !
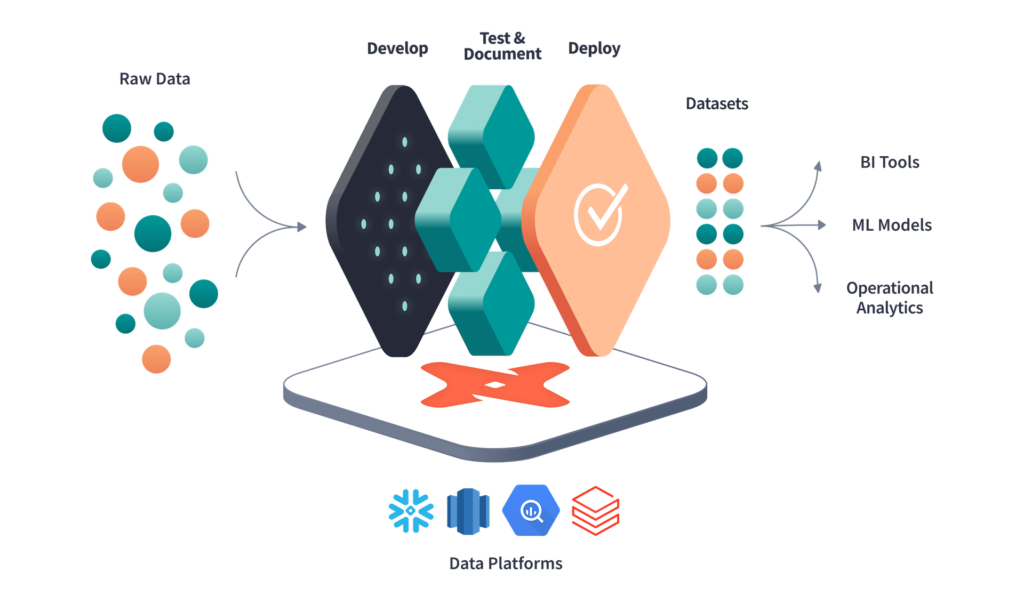
Des outils comme Dbt permettent aujourd’hui d’orchestrer des séries de transformations.
The analytics engineering workflow – DBT
L’introduction de la jointure flux-flux permet de gérer les mises à jour dimensionnelles et réduit la nécessité d’utiliser des modèles de réconciliation. Les bases de données en continu vont encore plus loin en faisant des flux de données en temps réel une partie intégrante du modèle de données. Cette architecture « Kappa » permet une approche simplifiée pour exploiter les données en temps réel.
Avec l’arrivée de solutions de bases de données MPP (comme Snowflake), les différences entre data lake, data warehouse et data lake house sont de plus en plus floues… et quoi qu’ils en soient, elles convergent (même si elles ne couvrent pas encore toutes les fonctionnées des entrepôts de données) pour faciliter certains cas de modélisation de données.
En somme, le data modeling a encore de beaux jours devant lui ! Et le rôle de l’ingénieur data n’a pas fini de se transformer.
Ops (ou Operators en anglais), c’est le buzzword qui n’en finit pas de buzzer. L’idée sous-jacente est de rendre tout « opérationnable » (c’est-à-dire aligné sur les priorités business pour créer plus de valeur). On a déjà le FinOps, le RevOps … mais parlons de XOps !
C’est le phénomène de fond qui agite le monde de l’ingénierie de la Data à laquelle nous appartenons chez Smartpoint. Il faut rappeler que Gartner l’a identifié dans son top des 10 tendances à suivre l’année dernière (à lire ici).
Déjà XOps comprend dans les faits DataOps, MLOps, ModelOps et PlatformOps.
Le principe ? Le XOps se base surles meilleurs pratiques du DevOps (et historiquement du lean) pour être plus efficace et faire des économies d’échelle.
L’objectif est de :
Automatiser pour accélérer et endiguer la duplication de technologies et la multiplication de processus (et autres workflows) dès que c’est possible
Concevoir une stack technologique de qualité, résiliente, réutilisable, évolutive et qui fonctionne dans la durée.
La nouveauté est qu’on intègre désormais l’IA et le ML … et surtout qu’on ne réfléchit plus à ce qui pourrait être rationalisé et automatisé à postériori mais bien dès la phase de conception.
Concrètement le XOps accélère l’ensemble des processus, lutte contre le gaspillage technologique et améliore la qualité des livrables des produits (DevOps et désormais DevSecOps), des données et leur analyse (DataOps) et des modèles d’IA (MLOps).
Dernier né des Ops ✨ ? Le ClouOps qui se concentre sur l’orchestration alors que les stratégies multi-cloud se développent dans les entreprises.
Bienvenue à la génération XOPS
Phénomène
Smart people, à la découverte des équipes.
0 commentaires
C’est comment chez le Pure Player de la Data ?
Nous vous proposons une visite guidée de Smartpoint en vidéo, à la rencontre de nos équipes 🎬
Cette vidéo été tournée au siège (Paris 13ème, rue neuve Tolbiac) en novembre dernier, avant les restrictions sanitaires dues à la 5ème vague.
Phénomène
Top 3 des tendances en stratégies analytiques et migrations data-to-the cloud
0 commentaires
Migrer en état vos traitements (workloads) qu’ils soient en Custom SQL (Python, Scala ou Java), en ETL Low-code (Fivetran ou Matillion par exemple) ou basés sur les technologies Hadoop (SPARK) peut sembler une bonne idée sur le papier… Mais dans les faits, vous ne faites que déplacer les enjeux de dette technologique et de réduction du TCO (total cost of ownership) des pipelines de données et … vous ne tirez pas pleinement partie des capacités des plateformes de dernière génération.
Voici trois best practice à suivre :
Une meilleure utilisation des outils en SaaS qui apportent une valeur ajoutée immédiate sans nécessiter – ou presque – d’administration, d’autant plus qu’ils offrent aujourd’hui des fonctionnalités avancées en termes de sécurité, d’optimisation des performances et de réplication.
La mise en œuvre des concepts DataOps dans vos cycles de développement tels que le contrôle de version et l’automatisation des builds, des tests et des déploiements.
Une meilleure exploitation des capacités des plateformes de Data Cloud qui permettent aujourd’hui le partage massif de données via des data marketplace, sans avoir à concevoir des pipelines pour échanger des extraits des fichiers, ni copier les données, ni développer et maintenir des API pour mettre à disposition les données aux ressources qui vont les consommer. Par exemple Snowflake Data Cloud propose plus de 400 data sets et une plateforme unique pour prendre en charge toute les données de manière sécurisée avec une gouvernance centralisée !
Pour aller plus loin sur notamment l’approche de l’ingénierie de données avec dbt (Data Build tool) en particulier et sur les solutions proposées par Snowflake, c’est ici.
Phénomène
2022, les tendances de la Data.
0 commentaires
Rituel de nouvelle année oblige, voici 6 grandes tendances Data qui devraient marquer 2022 avec pour toile de fond un cloud toujours plus omniprésent, une informatique quantique qui devrait enfin sortir des cartons, un développement soutenu des tissus de données (Data Fabrics) et de son corolaire maillage de données (Data Mesh).
Data Fabric, un environnement qui permet de réconcilier toutes les sources de données et Data Mesh, une approche d’architecture distribuée dynamique qui consiste à spécifier un domaine par sa création, le stockage et le catalogage des données afin qu’il soit exploitable par tous les utilisateurs d’autres domaines.
les Data Platformscloud-natives « as-a-service » qui apportent élasticité, performance et évolutivité. Elles devraient porter 95% des projets de transformation numérique des entreprise à horizon 2025 vs. 40% cette année.
L’hyper-automatisation et l’apprentissage automatique. Diminuer l’intervention humaine, pour la concentrer sur ce qui apporte le plus de valeur ajoutée, permet d’accélérer le time-to-market. Le développement de l’apprentissage automatique (ML) dans tous les processus métiers où il peut être embarqué est déjà une tendance forte qui devrait, sans surprise, s’accentuer sur toutes les tâches qui peuvent l’être. Cela permet aussi de gagner en capacités décisionnelles.
En parlant de BI (Business Intelligence), elle devrait continuer à se développer et à se démocratiser au-delà des seules grandes entreprises (PME). Plus facile d’accès, solutions moins chères aussi, elle se met de plus en plus au service du pilotage par la performance. Il en est de même de l’analyse prédictive (+ 20% sur 5 ans cf source ci-dessous)
l’ingénierie d’Intelligence Artificielle (IA) qui devrait permettre aux 10% des entreprises qui l’auront mise en pratique de générer trois fois de valeur que les 90% qui ne l’auront pas fait (toujours selon Gartner).
Small Data (vs. Big Data) dont l’objectif est de se concentrer sur la collecte et l’analyse de données vraiment utiles (et non de capter par principe massivement toute les données) … Vers une approche plus rationnelle, réfléchie, plus responsable et économe auquel nous sommes très attachés chez Smartpoint.
Quelles solutions à suivre en cette année 2022 ? Informatica, Microsoft toujours (notamment sur l’automatisation avec Power Automate), Qlik et Denodo pour n’en citer que 4 !
En clair, les années passent … mais l’enjeu reste le même. En revanche, il a gagné en criticité au fur et à mesure que les entreprises ont réalisé que les données sont une ressource stratégique, quel que soit leur secteur d’activité. Leur capture, leur gestion, leur gouvernance, leur exploitation et leur valorisation restent le défi N°1.
D’ailleurs, parmi les 12 tendances de Gartner pour 2022, 5 concernent la Data !