Outils Data
Comment choisir la bonne solution pour vous ? Déjà, ces produits ne sont pas – en théorie – comparables en termes d’usages.
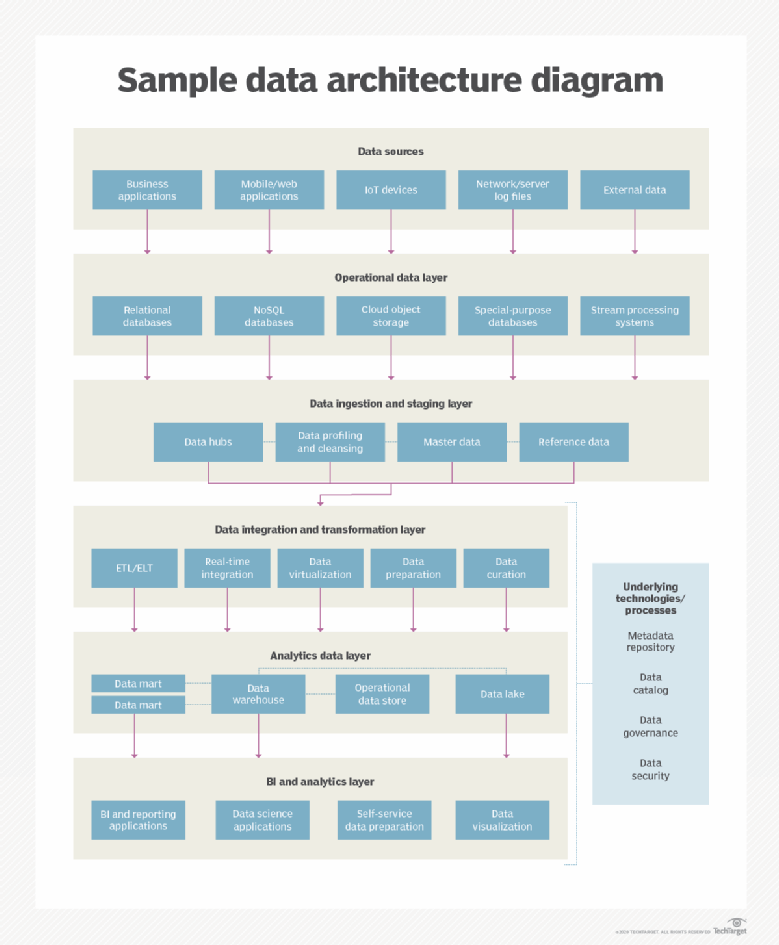
Snowflake est un Data Warehouse dans le cloud (SaaS) qui permet de collecter et de consolider les données dans un endroit centralisé à des fins d’analyse (Business Intelligence). Il est opérable avec les principaux clouders (Azure, GCP, AWS).
Comme pour un entrepôt de données classique, on utilise SQL pour faire des requêtes, créer des rapports et des tableaux de bord. Nous sommes clairement dans l’analyse et le reporting. Il a d’ailleurs été créé pour optimiser les performances des DWH traditionnels et faciliter la tâche des analystes. En revanche, il n’est pas optimisé pour traiter du Big Data en flux continu à date… même s’il est dans la roadmap de l’éditeur de s’ouvrir à d’autres langages comme Java, Python et Scala et de prendre en charge des données non structurées.
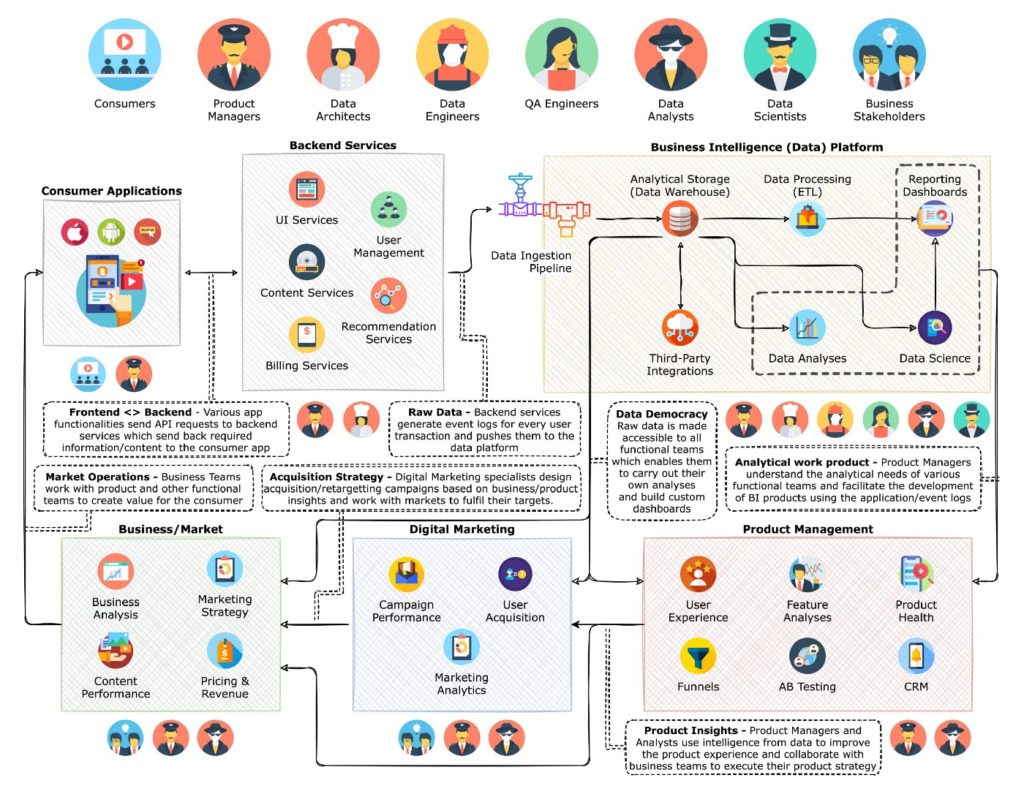
Databricks n’est pas un data warehouse … mais un data lake dédié aux environnements Big Data où il faut stocker de fortes volumétries de données brutes non traitées. Cette solution est à privilégier en Machine Learning, en streaming de données (ELT) et en data science. Elle supporte plusieurs langages de développement mais nécessite des compétences avancées en ingénierie de la data.
Basé sur Spark, Databricks peut faire tout ce que fait Snowflake et plus encore… mais cela reste un outil complexe ! L’optimisation de la plateforme et la conception d’un lake house fonctionnel prend du temps et la maintenance est loin d’être aisée, contrairement à Snowflake.
Snowflake et databricks ne sont également pas comparables en termes d’architectures.
Snowflake est une solution serverless avec des couches séparées pour le stockage et le traitement des données à l’aide de clusters de calcul composés de plusieurs nœuds MPP. Tout est automatisé : taille des fichiers, compression, structure, métadonnées, statistiques (…) objets qui ne sont pas directement visibles par l’utilisateur et auxquels on ne peut accéder que par des requêtes SQL.
Databricks est aussi une solution serverless en SaaS et fonctionne aussi sur Azure, AWS et GCP … mais l’architecture, basée sur Spark, est complètement différente avec :
- Le delta lake avec 3 types de tables : Bronze pour les données brutes, Silver pour celles nettoyées mais impropres à la consommation en état et les Gold pour les propres
- Le Delta Engine, un moteur de requête haute performance pour optimiser les charges de travail.
- Notebooks qui comprend du code réutilisable et qui permet via une interface web de construire des modèles en utilisant Scala, R, SQL et Python.
- ML Flow qui permet de configurer des environnements ML et d’exécuter des tests à partir de bibliothèques existantes.
Source : https://medium.com/operationalanalytics/databricks-vs-snowflake-the-definitive-guide-628b0a7b4719