Stack technologique
Cette année aura été marquée par les consolidations entre les éditeurs, les rachats ou le développement de fonctionnalités pour des outils existants pour couvrir de nouvelles briques de la data stack. Détails.
Ingestion
Cette couche couvre le streaming de données et les services SaaS qui permettent de mettre en place des pipelines de données des systèmes opérationnels jusqu’au stockage. Airbyte (open source) sort du lot avec une croissance exponentielle en termes d’entreprises utilisatrices (plus de 15 000) et le lancement d’un outil de Reverse ETL (via acquisition de Grouparoo).
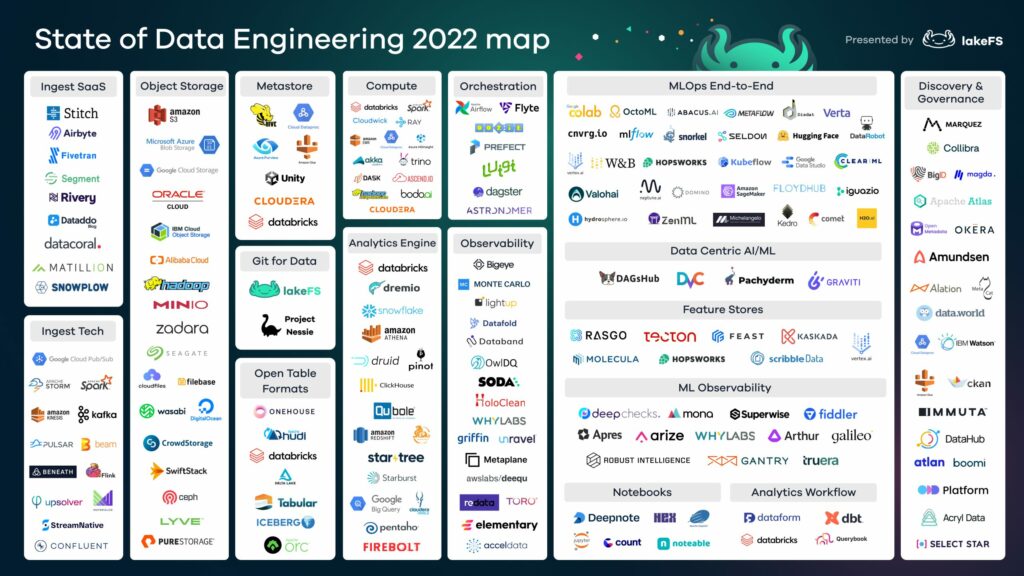
Datalakes
Dans cette segmentation de technologies, on part du principe qu’un datalake est un moteur d’analyse (bien que dans Databricks, cela inclut à la fois le data lake et le moteur d’analyse). Cette architecture permet d’optimiser Spark SQL pour créer un moteur analytique sur le format de table Delta. Cette même logique s’applique à Dremio sur Iceberg, ou à Snowflake supportant Iceberg comme tables externes à sa base de données.
Gestion des métadonnées
Dans cette couche, on retrouve les formats Open Table qui sont en train de devenir la norme pour prendre en charge les données structurées dans un datalake. Il y a un an, Delta Lake était un projet de Databricks avec un produit commercialisé sous le nom de Delta. Aujourd’hui, nous avons Apache Hudi commercialisé par Onehouse et Apache Iceberg commercialisé par Tabular. Ces deux sociétés ont été fondées par les créateurs de ces deux projets open-source.
Git pour la data
Le concept de Git pour les données s’installe dans la communauté des ingénieurs data. dbt encourage les analystes à utiliser les meilleures pratiques sur différentes versions de données (dev, stage et production), mais ne prend pas en charge la création et la maintenance de ces jeux de données dans les data lakes.
Les équipes DataOps cherchent de plus en plus à avoir un contrôle de version des données inter-organisations afin de mieux contrôler les différents jeux de données qui ont différentes révisions au fil du temps. Pour exemples de révisions courantes de jeux de données : le recalcul nécessaire pour les algorithmes et les modèles ML, ou de backfills provenant de systèmes opérationnels comme cela arrive souvent en BI, ou la suppression d’un sous-ensemble en raison de réglementations telles que le droit à l’oubli dans le cadre du GDPR.
Computing
Dans ce tableau, la partie virtualisation a été supprimée car elle a moins de vent en poupe ! On y retrouve les technologies de calculs distribués et les moteurs d’analyse.
La principale différence entre ces deux catégories est comment ces outils positionnement leur couche de stockage :
- Les moteurs de calcul distribué traditionnels permettent aux ingénieurs de distribuer tout ce qui est SQL ou tout autre code. Au-delà de Spark, les deux outils à suivre dans cette catégorie sont Ray et Dask. Ray est un projet open-source qui permet aux ingénieurs de mettre à l’échelle toute charge de travail Python à forte intensité de calcul, utilisée principalement pour l’apprentissage automatique. Dask est également un moteur Python distribué basé sur Pandas.
- La catégorie des moteurs d’analyse comprend tous les entrepôts de données tels que Snowflake, BigQuery, Redshift, Firebolt et toujours PostgreSQL. Elle contient également des entrepôts de données comme Databricks lakehouse, Dremio, ou Apache Pinot. Tous les moteurs d’analyse utilisent le datalake comme leur source de stockage. Il est à noter que Snowflake prend désormais en charge Apache Iceberg comme l’un des formats de table externe qui peut être lu par Snowflake directement à partir du datalake.
Orchestration
Airflow reste le plus produit open-source le plus populaire. Astronomer le talonne depuis quelques années déjà et depuis que la société a sauté dans le train du cloud, elle est maintenant en concurrence directe avec les principaux fournisseurs de cloud. À noter que Astronomer a également fait l’acquisition de Datakin qui fournit du data lineage. Que se passe t’il lorsqu’un outil d’orchestration a des capacités de lignage ? En théorie, cela pourrait permettre de construire des pipelines plus sûrs et plus résilients. En comprenant quels sont les ensembles de données qui sont impactés par des données manquantes, corrompues ou de mauvaise qualité, cela faciliterait considérablement l’analyse d’impact en liant la logique (gérée par les outils d’orchestration) et la sortie (gérée dans les outils de lignage). À suivre donc !
Observabilité
Cette catégorie est dominée par Monte Carlo qui a effectué plusieurs levées de fonds. Ce produit ne cesse d’évoluer, offrant davantage d’intégrations notamment avec l’écosystème databricks.
Data science
Cette catégorie comprend trois grandes familles d’outils :
- Les end-to-end ML Ops. Il semble que dans les faits, aucun de ces outils ne soient vraiment « de bout en bout » du pipeline de ML mais certains sont sur la bonne voie dont Comet.
- Data centric ML. Deux nouveaux entrants à suivre (toujours selon LakeFS) en termes d’outils avec Activeloop et Graviti.
- L’ observabilité et monitoring ML, il s’agit de tous les outils orientés suivi et observabilité de la qualité des modèles. Tout comme la catégorie de l’observabilité des données, c’est une catégorie d’outils en plein développement. A noter que début de 2022, Deepchecks est devenu open source et a rapidement gagné en adoption.
Data Catalog
C’est devenu un incontournable ! On retrouve les désormais acteurs de longue date comme Alation et Collibra. À suivre Immuta qui se concentre sur le contrôle de l’accès aux données mais qui a fait une importante levée de fonds pour accélérer sa croissance.
Article source https://lakefs.io/the-state-of-data-engineering-2022/