Stack technologique
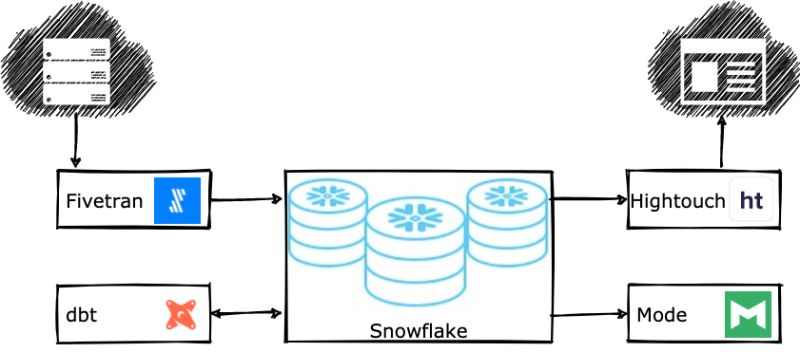
Pour raccourcir au maximum le temps de mise à disposition des données aux ressources qui vont les exploiter, une data stack moderne cloud native – et agile par nature – comprend aujourd’hui :
- Un data warehouse dans le cloud (ie Snowflake, BigQuery, Redshift, Databricks Delta Lake)
- Un outil d’intégration de données (Fivetran, Segment, Airbyte ELT open source)
- Un outil de transformation de données (dbt, Dataform)
- Une couche BI (comme Looker ou Mode)
- Un outil Reverse ETL (Census ou Hightouch)
Attention, le fait de porter votre plateforme BI dans le cloud (Lift and shift) ne suffit pas pour autant à la rendre moderne car c’est bien l’architecture qui doit être repensée !
Tous les composants qui participent à cette pile technologique moderne ont des caractéristiques communes. Déjà ils sont exposés as-a-service, orientés flux de production, les données sont centralisées dans le cloud data warehouse et on privilégie un écosystème SQL, le langage maîtrisé par le plus grand nombre. Ils fonctionnent sur des elastic workloads ou charges de travail élastiques pour plus de scalabilité (et du pay-per-use !).
Et pour 2022 ? Voici le top des 5 technologies les plus innovantes qui devraient venir enrichir votre pile technologique Data dans le cloud :
- Une couche d’intelligence artificielle
- Le partage de données ou data-as-a-service sous forme d’API
- La gouvernance de données, toujours plus indispensable dans les grandes entreprises qui cumulent des ensemble de données très diverses et privilégient une approche multi-cloud
- Le streaming de données pour tendre toujours plus vers un accès et une exécution temps réel des données
- Le service aux applications
Source : Data Stack, 5 prédictions pour le futur https://medium.com/@jordan_volz/five-predictions-for-the-future-of-the-modern-data-stack-435b4e911413