Architecture

Entre les promesses non tenues des Data Lakes, les ETL vieillissants et les plateformes cloud sous-exploitées, de nombreuses entreprises subissent une forte dette technique : leur architecture data ne suit plus le rythme des demandes métiers. Le modèle Médaillon, popularisé par Databricks, s’impose comme une solution intéressante et structurante pour reprendre le contrôle sur le cycle de vie de la donnée.
La modernisation des architectures data s’est souvent résumée à un empilement de technologies : ingestion par API, stockage S3, moteur Spark, outil BI, scripts SQL … Mais sans cadre structurant, cette complexité finit par générer l’effet inverse de celui recherché : une dette croissante, des pipelines data fragiles, une gouvernance floue, et des métiers désorientés.
Dans une économie pilotée par les données, où chaque décision, chaque automatisation ou modèle d’IA doit s’appuyer sur des pipelines fiables, une dette data non maîtrisée est un véritable risque.
Le modèle Médaillon, fondé sur une architecture en couches (Bronze, Silver, Gold), ne se contente pas de rationaliser les pipelines de données. Il impose une discipline d’ingénierie data à l’échelle de l’entreprise, une logique de valeur progressive de la donnée, et un socle gouverné, prêt pour la scalabilité et la conformité.
Quelles sont les solutions pour les DSI ? Continuer à colmater son legacy avec des outils modernes mal intégrés ? Ou basculer vers une approche très structurée pour sortir durablement du cercle dette / dérive / refonte ?
La promesse déçue des Data Lakes
Les Data Lakes ont longtemps représenté une alternative moderne aux entrepôts de données traditionnels : ingestion massive, prise en charge de tout type de données, faible coût de stockage… mais sans réelle structuration, beaucoup se sont transformés en data swamps. Résultat : des pipelines de données complexes, une faible qualité de données, une gouvernance difficile, et des plateformes incapables de soutenir les technologies d’IA ou les ambitions des métiers.
Face à l’empilement de solutions hétérogènes, à la dette technique croissante et à la pression des métiers, de plus en plus de DSI et de Responsables Data se trouvent dos au mur : repenser l’architecture data est une nécessité. En réponse, le modèle Médaillon apparait comme un cadre structurant, capable de redonner cohérence, fiabilité et gouvernance à l’ensemble du cycle de vie des données.
Architecture Médaillon : une solution progressive et gouvernée
L’architecture Médaillon repose sur le principe de raffinement successif de la donnée via trois couches distinctes :
- Bronze : Données brutes, telles qu’ingérées.
- Silver : Données nettoyées, normalisées et enrichies.
- Gold : Données business-ready, prêtes pour la BI, l’IA ou les dashboards.
Pensée pour les architectures Lakehouse comme Databricks, elle permet une mise en qualité progressive de la donnée, tout en assurant traçabilité, gouvernance et performance.
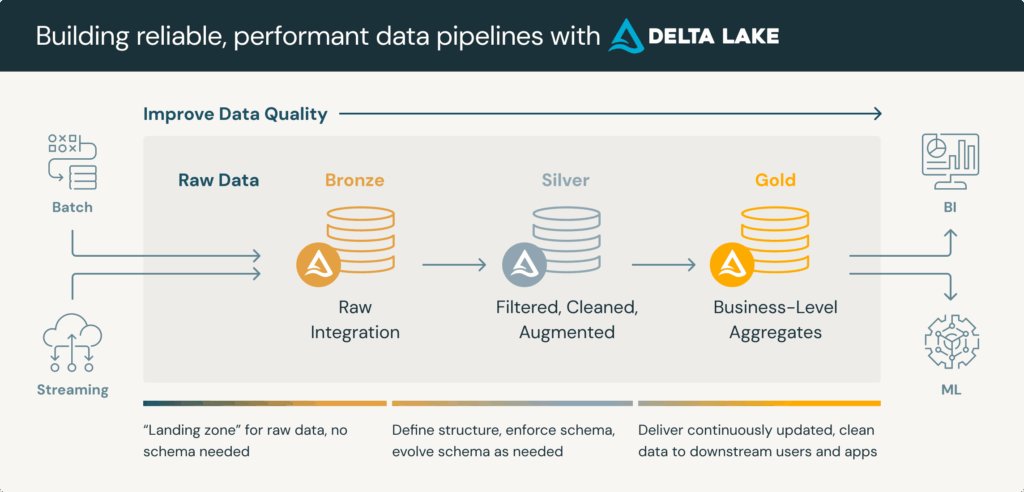
Zoom sur les couches Médaillon
L’architecture Médaillon repose sur une organisation des données en trois couches successives, Bronze, Silver et Gold (raw → clean → curated), chacune apportant un niveau croissant de structuration, de qualité et de valeur métier.
Bronze : données brutes traçables
La couche Bronze constitue le point d’entrée des données dans le système. Elle stocke les données dans leur format d’origine, sans aucune transformation, selon une logique append-only. Ce mode de stockage garantit la traçabilité des données, tout en assurant la reproductibilité des traitements en cas de besoin. On y retrouve des données issues de sources très diverses : APIs, fichiers plats, logs applicatifs, objets connectés (IoT), etc. Cette couche est le socle d’historisation et de fiabilité.
Silver : nettoyage, validation et enrichissement
La couche Silver, c’est le cœur opérationnel de cette architecture Data. Elle traite les données brutes issues de Bronze pour les nettoyer, valider et enrichir selon les besoins métiers ou analytiques. Les opérations types comprennent le dédoublonnage, la standardisation des formats ainsi que les vérifications des règles métiers. C’est également lors de cette étape que les données sont structurées dans des schémas exploitables, prêtes à être croisées ou analysées. La couche Silver délivre des datasets fiables pour les data discovery, la BI ou la data science.
Gold : données métiers optimisées
La couche Gold représente le niveau de raffinement optimal : les données sont agrégées, enrichies et modélisées selon les besoins spécifiques des utilisateurs métiers. On y retrouve des indicateurs clés (KPIs) et les vues agrégées. Ces datasets sont pensés pour une consommation immédiate via des outils de BI, des tableaux de bord, ou des applications IA. C’est la couche la plus exposée du pipeline, celle qui transforme les données en actifs décisionnels.
Pourquoi choisir la plateforme Databricks ?
L’architecture Médaillon révèle toute sa valeur ajoutée tout son sens lorsqu’elle est intégrée dans une plateforme unifiée. Databricks, qui a popularisé ce modèle, offre l’une des implémentations les plus matures et les plus opérationnelles. L’ensemble de ses briques techniques a été conçu pour s’aligner nativement sur le schéma Bronze / Silver / Gold, tout en permettant une scalabilité cloud, une gouvernance fine et le développement de l’IA.
1. Delta Lake, socle transactionnel
Delta Lake est le moteur de stockage et de traitement unifié de Databricks. Il permet d’enregistrer les données dans un format transactionnel ACID, avec la gestion de versions, le time travel (retour à un état antérieur de la donnée), et le support natif du streaming comme du batch. Chaque couche du modèle Médaillon peut être ainsi versionnée, historisée et auditée.
2. Delta Live Tables, automatisation des pipelines
Delta Live Tables (DLT) permet de créer des pipelines de transformation déclaratifs, orchestrés automatiquement par la plateforme. L’enchaînement Bronze → Silver → Gold est modélisé comme un workflow vivant, observable, testé, monitoré, et réexécutable à la demande. Cette brique limite les erreurs humaines et standardise les pipelines data dans un environnement multi-équipe.
3. Unity Catalog , centralisation de la gouvernance
Unity Catalog est la solution de gouvernance des data products de Databricks. Il centralise la gestion des métadonnées, des schémas, des politiques d’accès (RBAC), et assure une traçabilité complète des usages. Il devient le backbone de la gouvernance dans des environnements multi-workspaces, multi-clusters ou multi-clouds.
4. MLflow pour les modèles IA en production
MLflow complète l’écosystème avec une solution native de gestion du cycle de vie des modèles IA : entraînement, suivi, déploiement, versioning… Les datasets Silver et Gold peuvent sont directement utilisés pour créer des features sets, entraîner des modèles ou réaliser des inférences. L’intégration avec Delta Lake garantit que les modèles consomment des données fiables, gouvernées et reproductibles.
Databricks, c’est une chaîne de valeur data / IA cohérente, intégrée, et gouvernée de bout en bout. La plateforme permet de standardiser les pipelines Data, de réduire la dette technique, et de scaler les cas d’usage métiers et IA sur une infrastructure robuste.
| Plateforme | Modèle Médaillon natif ? | C’est pour vous si : |
| Databricks | Oui (intégré nativement) | Vous cherchez une solution unifiée Data + IA + gouvernance |
| Snowflake | Non, mais possible | Vous avez un stack SQL/dbt |
| BigQuery | Non, mais possible | Vous êtes dans l’écosystème Google et voulez développer l’IA |
| Azure Synapse | Non, mais possible | Vous êtes dans un environnement Microsoft / Power BI |
L’architecture Médaillon vs. ETL
Il est intéressant de comparer Médaillon avec les autres approches de transformation des données :
| Critère | ETL Classique | ELT | Architecture Médaillon |
| Type de données | Structurées uniquement | Structurées | Tous formats (JSON, CSV, IoT, etc.) |
| Flexibilité | Faible (workflow rigide) | Moyenne (transformations en SQL) | Forte (multi-langages, multi-formats, modulaire) |
| Temps réel | Non | Parfois (ajouté a posteriori) | Oui (streaming natif avec Spark) |
| Gouvernance | Manuelle | Partielle (dépend de la plateforme) | Complète avec métadonnées, lineage |
| Maintenance | Complexe à maintenir | Variable, dépend des outoms | Modulaire, versionnable, traçable |
Contrairement aux approches plus classiques, l’architecture Médaillon est nativement compatible avec le cloud, les workloads IA, la BI et répond aux contraintes réglementaires.
Gouvernance, sécurité et qualité de données
L’architecture Médaillon permet d’automatiser la gouvernance, couche par couche :
- Bronze : gestion des sources, métadonnées techniques
- Silver : logs de validation, transformation documentée
- Gold : politiques d’accès RBAC, journalisation des consultations, KPIs traçables
Elle offre un cadre de conformité natif avec le RGPD, grâce à une traçabilité fine, un contrôle granulaire des accès et une gestion encadrée des données personnelles sensibles.
Architecture Médaillon et traitement temps réel
L’architecture Médaillon n’est pas limitée aux traitements batch ou à des usages différés. Elle supporte aussi les pipelines temps réel, : ingestion continue transformation à la volée, exposition des data prêtes à l’usage.
L’ingestion des données en temps réel peut être faite avec des technologies comme Apache Kafka, Azure Event Hubs ou Google Pub/Sub, qui alimentent directement la couche Bronze. Ces flux continus sont ensuite traités dans la couche Silver grâce à des moteurs comme Spark Structured Streaming, qui permettent de nettoyer, d’enrichir et de transformer les données.
Enfin, la couche Gold agrège ces données en quasi temps réel pour produire des indicateurs métiers ou déclencher des actions automatisées. L’architecture Médaillon permet un raffinement progressif même dans un contexte streaming, tout en maintenant les principes de traçabilité et de gouvernance.
Quelques cas d’usages : suivi logistique en temps réel (colis, flotte, IoT), pricing dynamique en fonction de la demande ou des stocks, détection de fraude sur des transactions.
Stratégie de modernisation de votre SI Data
La mise en place d’une architecture Médaillon s’inscrit souvent dans un projet plus large de modernisation du système d’information data.
Plusieurs facteurs peuvent motiver cette décision.
Parmi eux, on retrouve fréquemment les attentes croissances des métiers en matière de BI, d’IA ou de fiabilité des données. La migration vers des environnements cloud est également un accélérateur car une architecture Médaillon offre une infrastructure scalable et adaptée aux workloads data. L’adoption de plateformes unifiées, comme Databricks, a également un rôle central car elle fournit les briques prêtes à l’emploi pour concevoir des pipelines gouvernés et industrialisés.
À l’inverse, certains facteurs peuvent freiner l’adoption d’une architecture Médaillon. C’est souvent le cas lorsque les données sont fortement silotées, peu documentées, ou réparties entre plusieurs systèmes hétérogènes. Les DSI avec un legacy particulièrement complexe, basé sur des ETL propriétaires, des bases cloisonnées ou des workflows complexes, ont également du mal à mettre en place des pipelines plus agiles. Enfin, le manque d’acculturation DataOps ou en gouvernance des données est également un frein.
Vers une architecture Data moderne, distribuée et gouvernée
L’architecture Médaillon est également un socle pour des approches data plus avancées, notamment dans des environnements distribués ou fortement orientés métiers.
Elle est particulièrement adaptée à l’approche Data Mesh, où chaque domaine métier est propriétaire de ses propres pipelines de données. Grâce aux couches Bronze / Silver / Gold, chaque équipe peut concevoir, gouverner et exposer des Data Products industrialisés, versionnés et traçables, tout en respectant un cadre commun de gouvernance à l’échelle de l’organisation.
L’architecture Médaillon facilite également la mise en œuvre d’une IA à l’échelle. Les données Silver, déjà nettoyées et enrichies, sont utilisées pour entraîner des modèles de machine learning. Quant à la couche Gold, elle est parfaitement adaptée au déploiement en production pour, par exemple, des prédictions en temps réel ou des systèmes de recommandation. L’intégration avec des outils comme MLflow (nativement supporté sur Databricks) permet d’assurer un pilotage complet du cycle de vie des modèles : de la phase d’expérimentation jusqu’au monitoring post-déploiement.
Architecture Médaillon, le socle d’un SI data-first
Adopter une architecture Médaillon, c’est prioriser la fiabilité des données, la gouvernance, la traçabilité et l’évolutivité. Alors que les entreprises cherchent à industrialiser leurs cas d’usage data, tout en maîtrisant les coûts, les risques et la conformité, l’architecture Médaillon s’impose.
Intégrée dans une plateforme comme Databricks, elle représente un véritable levier de transformation pour la BI, l’IA, le reporting réglementaire, et la migration cloud.
Smartpoint vous accompagne sur toute la chaîne de valeur :
- Cadrage de votre architecture data
- Déploiement de Databricks et pipelines Médaillon
- Mise en œuvre de Unity Catalog, DataOps, MLOps
- Migration progressive de vos systèmes legacy
- Formations et acculturation de vos équipes Data & Métiers
Contactez-nous pour valoriser vos actifs data grâce à une architecture résiliente, agile… prête à supporter tous vos projets d’avenir.
Sources :
- Qu’est-ce que l’architecture de médaillon dans un lakehouse ? https://learn.microsoft.com/fr-fr/azure/databricks/lakehouse/medallion
- Implémenter l’architecture de lakehouse en médaillon dans Microsoft Fabric https://learn.microsoft.com/fr-fr/fabric/onelake/onelake-medallion-lakehouse-architecture
- Architecture en médaillon https://www.databricks.com/fr/glossary/medallion-architecture
LAISSEZ-NOUS UN MESSAGE
Les champs obligatoires sont indiqués avec *.